
Инженерный тур. 3 этап
Задача третьего этапа — разработка системы уведомлений операторов колл-центра Департамента безопасности Сбера о подозрительных банковских транзакциях. Итогом работы является готовый программный комплекс, включающий алгоритм поиска мошеннических операций, архитектуру сервиса и рабочую версию веб-интерфейса с интеграцией в Telegram, позволяющие оперативно реагировать на потенциально мошеннические операции.
Участники анализируют предоставленную банком базу данных банковских транзакций, изучают ее структуру и создают алгоритм для поиска ID-мошенника, а также разрабатывают архитектуру системы, предназначенной для визуализации подозрительных транзакций и отправки уведомлений операторам. Команда пишет код системы, создает веб-интерфейс для операторов колл-центра, настраивает интеграцию с Telegram для автоматизированных уведомлений.
Функциональность системы может варьироваться от реактивной модели, когда система реагирует на уже свершившиеся мошеннические операции, до проактивной модели, которая прогнозирует потенциальные риски. Можно внедрить объяснимый ИИ, чтобы операторы могли интерпретировать результаты, а также реализовать дашборды и графовые модели связей транзакций для наглядного анализа данных.
Георгий — студент ИТМО, мечта которого — начать свой карьерный путь с ПАО Сбербанк. Как победителя Олимпиады его пригласили на стажировку в департаменте ИТ-блока «Сеть продаж» (ДИТ). ДИТ отвечает за ПО в банкоматах и офисах Сбера, а также добавляет в сервисы функционал ИИ.
Во время стажировки Георгий узнал, что Сбер сейчас проводит ежегодный хакатон «Лучший по профессии», и попросился в команду вместе с более опытными товарищами. Коллеги рассказали, что это отличный способ прокачать свои скиллы, создать полезный в реальности продукт и помочь команде получить очередную, шестую, медаль в зал славы ДИТ «Сеть продаж», обогнав остальные департаменты. А для Георгия лично это отличный шанс показать себя и быть в будущем зачисленным в штат!
Команде и Георгию выпало серьезное задание — борьба с телефонным мошенничеством. Как найти мошенника, его контакты и других его жертв и разработать алгоритм борьбы с социальным инжинирингом, который будет использоваться в реальной жизни?
Количество участников в команде: 3–5 человек.
Компетенции, которыми должны обладать члены команды:
- Капитан: координирует работу команды, собирает и анализирует решения подзадач от всех специалистов, принимает ключевые решения по архитектуре системы и стратегиям выявления мошенничества; обеспечивает согласованность между этапами разработки и отвечает за итоговую интеграцию всех компонентов.
- SQL-программист: отвечает за работу с базой данных, включая написание сложных SQL-запросов, оптимизацию производительности и настройку структуры данных; разрабатывает алгоритмы для выявления мошеннических транзакций и интегрирует их с другими модулями системы. Данная роль может выполняться несколькими членами команды.
- Разработчик бэкенда: создает серверную часть системы, включая API, логику обработки данных и интеграцию с Telegram; отвечает за реализацию триггеров и подключение машинного обучения, обеспечивая стабильную и безопасную работу сервиса.
- Разработчик фронтенда: разрабатывает веб-интерфейс оператора колл-центра, создает удобную визуализацию подозрительных транзакций и обеспечивает интеграцию с бэкендом. Отвечает за удобство работы операторов и интуитивный пользовательский опыт.
| Наименование | Описание |
|---|---|
| Оборудование | Персональные компьютеры/ноутбуки с Windows, macOS или Linux. Доступ в интернет. Возможность локального запуска БД и серверов. (При необходимости) смартфон с Telegram для тестирования уведомлений. |
| Язык программирования | Python 3.8+, SQL, (при необходимости Java, Javascript, HTML и другие на усмотрение участников финала). |
| Базы данных (СУБД) | SQLite, PostgreSQL (или другие реляционные СУБД). |
| Среды разработки | Visual Studio Code, PyCharm, Jupyter Notebook. |
| Фреймворки (бэкенд) | FastAPI Flask (или другие фреймворки на усмотрение участников финала). |
| Фреймворки (фронтенд) | React/Vue (или другие фреймворки на усмотрение участников финала). |
| API-инструменты | Telegram Bot API — для отправки уведомлений операторам, Swagger/Redoc — для документирования API. |
| Контейнеризация (опционально) | Docker (не обязателен, но может быть использован для контейнеризации проекта). |
| Система контроля версий | Git/GitHub — для хранения кода и совместной работы. |
| Инструменты визуализации | Miro, draw.io, Lucidchart (для диаграмм и архитектуры), Paint или аналоги для визуализации архитектуры и взаимодействия компонентов. |
| Документирование | Microsoft Office/Libre Office/Google Docs и др., Markdown, PDF — для оформления отчетных и презентационных материалов. |
| Демонстрация проекта | Zoom, запись видео экрана с демонстрацией запуска проекта |
Георгий — студент ИТМО, мечта которого — начать свой карьерный путь с ПАО Сбербанк. Как победителя Олимпиады его пригласили на стажировку в департаменте ИТ блока «Сеть продаж» (ДИТ). ДИТ отвечает за ПО в банкоматах и офисах Сбера, а также добавляет в сервисы функционал ИИ.
Во время стажировки Георгий узнал, что Сбер сейчас проводит ежегодный хакатон «Лучший по профессии» и попросился в команду вместе с более опытными товарищами. Коллеги рассказали, что это отличный способ прокачать свои скиллы, создать полезный в реальности продукт и помочь команде получить очередную, шестую, медаль в зал славы ДИТ «Сеть продаж», обогнав остальные департаменты. А для Георгия лично это отличный шанс показать себя и быть в будущем зачисленным в штат!
Команде и Георгию выпало серьезное задание — борьба с телефонным мошенничеством. Как найти мошенника, его контакты и других его жертв и разработать алгоритм борьбы с социальным инжинирингом, который будет использоваться в реальной жизни?
Требуемые результаты решения задачи: команда должна разработать систему обнаружения подозрительных банковских транзакций и уведомления об этом для операторов колл-центра банка. Итогом работы является готовый программный комплекс, включающий:
- алгоритм поиска мошеннических операций;
- архитектуру сервиса;
- рабочую версию веб-интерфейса с интеграцией в Telegram.
Техническое задание:
- База данных банковских транзакций, содержащая параметры платежей и метаданные клиентов.
- Описание типов мошеннических операций и требований к обнаружению аномалий.
- Требование к отправке уведомлений операторам через Telegram и веб-интерфейс.
- Ожидание возможной интеграции с машинным обучением и триггерами для повышения точности детекции.
Ограничения:
- Запросы к базе данных должны быть оптимизированными для быстрого выполнения.
- Уведомления должны отправляться в реальном времени или с минимальной задержкой.
- Веб-интерфейс должен обеспечивать удобство работы операторов и быть защищен от несанкционированного доступа.
- Внедрение машинного обучения возможно, но должно учитывать интерпретируемость решений для операторов.
- Система должна быть масштабируемой и устойчивой к нагрузкам.
Этап 1. Аналитика
- Проанализировать структуру базы данных банковских транзакций (предоставлена организаторами).
- Разработать алгоритм поиска ID мошенника на основе транзакционных данных.
- Оценить возможные критерии мошеннических действий (например, частота транзакций, географические аномалии, переводы на подозрительные счета).
- Подготовить программный код поиска мошенника и представить результат в виде ID мошенника.
Этап 2. Разработка архитектуры сервиса
- Спроектировать архитектуру системы (взаимодействие базы данных, бэкенда, фронтенда, Telegram-уведомлений).
- Разработать диаграмму вариантов использования для операторов колл-центра.
- Выбрать технологии для реализации (база данных, серверный фреймворк, UI-библиотеки, интеграция с Telegram API).
- Разработать структуру API и определить методы для обработки транзакций.
- Создать макет веб-интерфейса оператора колл-центра.
- Спроектировать механизм отправки уведомлений в Telegram на основе событий в системе.
- Описать потенциальное масштабирование системы.
Этап 3. Реализация проекта
- Разработать бэкенд: REST API, обработка запросов, бизнес-логика.
- Разработать веб-интерфейс оператора, отображающий подозрительные транзакции и их параметры.
- Настроить интеграцию с Telegram для отправки автоматизированных уведомлений.
- Реализовать механизмы триггеров и базовые алгоритмы машинного обучения для выявления аномалий (по желанию команды).
- Доработать интерфейс возможностью фильтрации данных (например, по периоду, сумме, клиенту) (по желанию команды).
- Публикация проекта в репозитории github.
- Оформление репозитория и создание инструкции по запуску проекта.
Каждый этап оценивается отдельно по 100-балльной шкале.
Оценивание происходит вручную, как средняя оценка экспертов по проекту, на основе критериев. Работа ведется в течение трех дней. Каждый этап оценивается отдельно.
- Дан неверный ответ, решения не предоставлено — 0 баллов.
- Описаны не менее трех ключевых параметров мошенничества как результат анализа базы данных; программный код не представлен, ответ верный или частично верный — 15 баллов.
- Разработан и описан алгоритм поиска личности мошенника, программный код представлен и задокументирован, ответ верный или частично верный — 25 баллов.
- Представлен корректный результат (личность мошенника), представлено алгоритм и корректно задокументированный программный код — 50 баллов.
Описание ключевых параметров мошенничества (максимально 20 баллов):
- 0 баллов — параметры не описаны или не соответствуют теме.
- 5 баллов — описан один параметр (например, сумма транзакции).
- 10 баллов — описаны два параметра, поверхностный анализ.
- 15 баллов — описаны три параметра, логично обоснованы.
- 20 баллов — описано более трех параметров, хорошо структурированы, с примерами и объяснением, почему они важны.
Разработка и описание алгоритма поиска мошенника (максимально 20 баллов):
- 0 баллов — алгоритм отсутствует.
- 10 баллов — представлен общий подход, но без конкретики.
- 15 баллов — алгоритм описан, но не оптимален или частично формализован.
- 20 баллов — четкий пошаговый алгоритм, реализуемый в SQL-коде, с обоснованием / логикой исключений / возможностью масштабирования или повторного использования.
Представление корректного результата (ID мошенника) (максимально 50 баллов):
- 0 баллов — ID не найден, ответ отсутствует или неверен.
- 15 баллов — ID найден правильно, но решение неполное (нет адреса, номера телефона или чего-то другого), нет адекватного вывода на экран.
- 25 баллов — ID найден правильно, но не подтвержден SQL-запросами / без пояснения логики решения.
- 50 баллов — ID найден правильно, подтвержден SQL-запросами и сопровождается понятным объяснением логики поиска.
Качество кода и документации (максимально 10 баллов):
- 0 баллов — код нечитаем, нет комментариев.
- 3 балла — код частично читаем, с минимальными комментариями.
- 6 баллов — код структурирован, соблюден базовый стиль, есть краткие пояснения.
- 10 баллов — код оформлен согласно стандартам, документирован, с пояснением логики.
Оценивание происходит вручную, как средняя оценка экспертов по проекту, на основе критериев. Работа ведется в течение трех дней. Каждый этап оценивается отдельно.
- Разработана диаграмма архитектуры системы — 10 баллов.
- Подготовлена диаграмма вариантов использования — 10 баллов.
- Выбраны технологии и обоснован их выбор — 10 баллов.
- Спроектирована структура API и определены методы — 10 баллов.
- Разработан прототип веб-интерфейса — 20 баллов.
- Реализован и обоснован механизм отправки уведомлений в Telegram — 15 баллов.
- Продуманы триггеры и алгоритмы для выявления подозрительных транзакций — 10 баллов.
- Описание архитектуры оформлено в документации — 10 баллов.
- Архитектурные решения позволяют дальнейшее масштабирование системы — 5 баллов.
Диаграмма архитектуры системы (максимально 10 баллов):
- 0 баллов — диаграмма отсутствует.
- 3 балла — диаграмма представлена, но неполная, отсутствуют ключевые компоненты.
- 6 баллов — указаны основные блоки (БД, фронт, бэк), но взаимодействие между ними не отражено.
- 8 баллов — указаны основные блоки (БД, фронт, бэк), потоки данные не документированы подробно, а представлены в общих чертах.
- 10 баллов — логичная, визуально чистая диаграмма, отражающая модули, взаимодействие, потоки данных и внешние сервисы (например, Telegram).
Диаграмма вариантов использования (максимально 10 баллов):
- 0 баллов — диаграмма не представлена.
- 5 баллов — диаграмма сделана, но не учитывает роли пользователя.
- 8 баллов — охвачены базовые сценарии использования (оператор, админ).
- 10 баллов — четко структурированная диаграмма с ролями, действиями, связями и комментариями.
Выбор технологий и обоснование (максимально 10 баллов):
- 0 баллов — список технологий отсутствует.
- 3 балла — указан список технологий без объяснения.
- 6 баллов — дано обоснование выбора одной-двух ключевых технологий.
- 8 баллов — приведены аргументы по стеку (БД, фронт, бэк, интеграции).
- 10 баллов — логично обоснован и согласован полный технологический стек с учетом масштабируемости и совместимости компонентов.
Структура API и описание методов (максимально 10 баллов):
- 0 баллов — API не описан.
- 5 баллов — описана структура API и основные методы.
- 10 баллов — полная спецификация API, соответствующая REST-принципам, описаны методы с параметрами, типами запросов и примерами.
Прототип веб-интерфейса (максимально 20 баллов):
- 0 баллов — отсутствует.
- 5 баллов — представлен общий макет (например, набросок в Paint).
- 10 баллов — создан кликабельный прототип или интерфейс в Figma/HTML.
- 15 баллов — прототип логичен, включает элементы фильтрации, уведомлений и отображения данных.
- 20 баллов — полнофункциональный и хорошо продуманный прототип, приближенный к финальной реализации.
Механизм уведомлений в Telegram (максимально 15 баллов):
- 0 баллов — не описан.
- 7 баллов — описан в общих чертах (обозначено наличие).
- 10 баллов — дано описание взаимодействия с системой.
- 15 баллов — дано пошаговое описание взаимодействия, прописано с учетом команд, описана логика взаимодействия.
Триггеры и алгоритмы выявления подозрительных транзакций (максимально 10 баллов):
- 0 баллов — отсутствуют.
- 5 баллов — определены простые условия (например, сумма больше X).
- 8 баллов — разработан набор бизнес-правил/триггеров на SQL или бэкенде.
- 10 баллов — учтены разные сценарии и вариации мошенничества или представлена подготовка к ML.
Документация по архитектуре (максимально 10 баллов):
- 0 баллов — отсутствует.
- 6 баллов — краткое текстовое описание.
- 10 баллов — четкая, структурированная документация с примерами и визуализациями/оформлено в Markdown/PDF, содержит блоки по основным модулям.
Масштабируемость архитектуры (максимально 5 баллов):
- 0 баллов — не учитывается масштабируемость.
- 2 балла — описаны общие идеи (например, «можно будет расширить следующие части...»).
- 5 баллов — предусмотрены конкретные механизмы масштабирования (например, микросервисы, очередь сообщений).
Код системы запускается без ошибок, и система реагирует на изменения в базе данных (максимально 25 баллов):
- Бэкенд реализован с использованием фреймворков — 10 баллов.
- Веб-интерфейс оператора реализован с использованием фреймворков — 10 баллов.
- Реализовано API для взаимодействия с веб-интерфейсом — 5 баллов.
- Интеграция с Telegram успешно работает — 10 баллов.
- Реализованы триггеры и/или алгоритмы машинного обучения как расширение базовой функциональности — 20 баллов.
- Реализована возможность фильтрации данных (например, по периоду, сумме, клиенту) и визуализации данных — 10 баллов.
- Код соответствует стандартам оформления — 5 баллов.
- Проект содержит инструкцию по запуску — 5 баллов.
Код запускается без ошибок, система реагирует на изменения в БД (максимально 25 баллов):
- 0 баллов — система не запускается, возникают критические ошибки/невозможно оценить реакцию на изменения в базу данных.
- 15 баллов — работает корректно, не проверялась реакция на изменения.
- 20 баллов — система стабильно запускается, корректно реагирует на обновления БД (например, по триггерам).
- 25 баллов — запускается без ошибок, стабильная работа, включен механизм автоматической обработки новых данных и отправки уведомлений в бот.
Бэкенд реализован с использованием фреймворков (максимально 10 баллов):
- 0 баллов — отсутствует или написан на чистом языке без структуры.
- 5 баллов — используется фреймворк, но архитектура проекта не соблюдена/вызывает вопросы.
- 10 баллов — использован фреймворк (например, Flask/FastAPI), код структурирован, соблюдены принципы проектирования, реализован REST.
Веб-интерфейс оператора реализован с использованием фреймворков (максимально 10 баллов):
- 0 баллов — веб-интерфейс отсутствует или представлен статичной HTML-страницей.
- 5 баллов — фреймворк не использован, но страница динамическая.
- 10 баллов — использован фреймворк (например, React/Vue), интерфейс интерактивный, подключен к API, выполнен на фреймворке, адаптирован под задачи оператора.
Реализовано API для взаимодействия с фронтендом (максимально 5 баллов):
- 0 баллов — API отсутствует.
- 2 балла — API реализовано частично, нестабильно или не по REST.
- 5 баллов — API полностью соответствует REST, стабильно работает, протестировано.
Интеграция с Telegram (максимально 10 баллов):
- 0 баллов — интеграция отсутствует.
- 5 баллов — Telegram-бот реализован, но не получается полностью подтвердить его корректность работу/не реагирует на изменения в базе автоматически.
- 10 баллов — Telegram-бот реализован, бот отправляет сообщения по событиям из БД, есть логика форматирования и связи с основной системой.
Триггеры и/или алгоритмы машинного обучения (максимально 20 баллов):
- 0 баллов — отсутствуют.
- 10 баллов — реализованы простые SQL-триггеры или правила.
- 20 баллов — подключена модель машинного обучения или сложная логика выявления аномалий.
Фильтрация данных во фронтенде (максимально 10 баллов):
- 0 баллов — фильтрация/визуализация отсутствует.
- 5 баллов — реализована базовая фильтрация по одному параметру, присутствует визуальное отображение одного параметра на странице.
- 10 баллов — реализована фильтрация по нескольким параметрам (дата, сумма и т. д.), присутствует визуализация всех ключевых параметров.
Соответствие кода стандартам оформления (максимально 5 баллов):
- 0 баллов — код не оформлен, отсутствуют комментарии.
- 3 балла — частично соблюдены правила, есть структура.
- 5 баллов — код структурирован, оформлен, читаем, прокомментирован, (PEP8 и др.), репозиторий оформлен корректно.
Инструкция по запуску проекта (максимально 5 баллов):
- 0 баллов — инструкция отсутствует.
- 3 балла — инструкция частичная или неполная.
- 5 баллов — полное описание установки и запуска в файле
README.md(или любом другом читаемом файле).
Балл технической части инженерного тура рассчитывается как среднее арифметическое трех этапов.
Максимальный балл за защиту проекта — 100 баллов.
Итоговая оценка инженерного тура (\(S\)) рассчитывается по формуле:
\[S = \frac{P_1 + P_2 + P_3}3 \times 80\% + P_r \times 20\%,\] где \(S\) — сумма, \(P_{1, 2, 3}\) — оценки этапов инженерного тура, \(P_r\) — оценка презентации проекта.
Дано: файлы базы данных банковских транзакций, содержащей параметры платежей и метаданные клиентов в формате .tsv.
На данном этапе необходимо:
- Проанализировать структуру базы данных банковских транзакций (предоставлена организаторами).
- Разработать алгоритм поиска ID мошенника на основе транзакционных данных.
- Оценить возможные критерии мошеннических действий (например, частота транзакций, географические аномалии, переводы на подозрительные счета).
- Подготовить программный код поиска мошенника и представить результат в виде ID мошенника.
Представленное решение является одним из возможных вариантов реализации и не претендует на статус единственно верного.
Оно иллюстрирует подход к решению задачи, но допускает альтернативные реализации, которые могут быть не менее корректными и эффективными.
Для решения задачи нужно создать базу данных SQLite и автоматически загрузить в нее данные из нескольких .tsv-файлов, преобразовав их в таблицы.
Ниже представлен код на языке Python и SQL для загрузки данных из файлов и создание базы данных SQLite.
import sqlite3
import pandas as pd
import os
# Путь к папке с файлами
data_dir = './samples' # замените на нужную папку
db_file = 'bank_data.db'
# Список файлов
files = [
'bank_clients.tsv',
'bank_complaints.tsv',
'bank_transactions.tsv',
'ecosystem_mapping.tsv',
'market_place_delivery.tsv',
'mobile_build.tsv',
'mobile_clients.tsv'
]
# Создание подключения к базе данных SQLite
conn = sqlite3.connect(db_file)
cursor = conn.cursor()
for file in files:
table_name = file.replace('.tsv', '')
file_path = os.path.join(data_dir, file)
# Загружаем TSV-файл в DataFrame
df = pd.read_csv(file_path, sep='\t')
# Сохраняем таблицу в базу данных
df.to_sql(table_name, conn, if_exists='replace', index=False)
print(f"Таблица '{table_name}' успешно создана из файла {file}")
# Закрываем соединение
conn.close()
print(f"База данных '{db_file}' успешно создана.")Вывод:
Таблица 'bank_clients' успешно создана из файла bank_clients.tsv
Таблица 'bank_complaints' успешно создана из файла bank_complaints.tsv
Таблица 'bank_transactions' успешно создана из файла bank_transactions.tsv
Таблица 'ecosystem_mapping' успешно создана из файла ecosystem_mapping.tsv
Таблица 'market_place_delivery' успешно создана из файла market_place_delivery.tsv
Таблица 'mobile_build' успешно создана из файла mobile_build.tsv
Таблица 'mobile_clients' успешно создана из файла mobile_clients.tsv
База данных 'bank_data.db' успешно создана.Что делает код:
- Устанавливает путь к папке с
.tsv-файлами и создает подключение к SQLite-базе данных (bank_data.db). - Перебирает список файлов, загружает каждый в
pandas.DataFrameс разделителем табуляция. - Преобразует имя файла в имя таблицы (без расширения
.tsv). - Сохраняет каждую таблицу в базу данных (с заменой, если уже существует).
- По завершении закрывает соединение и выводит сообщения об успешной загрузке.
Результат: готовая база данных SQLite, содержащая семь таблиц, соответствующих исходным .tsv-файлам.
views</div> ) на основе загруженных данных и решение задачиПредложим вариант решения — создать серию представлений (views) в базе данных SQLite на основе ранее загруженных таблиц, объединяя данные из разных источников в единую структуру для анализа связей между клиентами, звонками, транзакциями и доставками.
# Подключение к базе данных
conn = sqlite3.connect('bank_data.db')
cursor = conn.cursor()
# SQL-скрипт для создания представлений
sql_script = """
DROP VIEW IF EXISTS client_profile;
CREATE VIEW client_profile AS
SELECT userId, fio, account, phone, mobile_user_id, market_plece_user_id
FROM (
SELECT userId, fio, account, phone
FROM bank_complaints INNER JOIN bank_clients USING (userId)
) INNER JOIN ecosystem_mapping ON userId = bank_id;
DROP VIEW IF EXISTS client_transactions;
CREATE VIEW client_transactions AS
SELECT userId, fio, account, account_out AS account_of_receiver, value, event_date
FROM client_profile INNER JOIN bank_transactions ON account = account_out;
DROP VIEW IF EXISTS client_calls;
CREATE VIEW client_calls AS
SELECT userId, fio, from_call AS incoming_call, duration_sec, event_date
FROM client_profile INNER JOIN mobile_build ON phone = to_call;
DROP VIEW IF EXISTS info_by_phone;
CREATE VIEW info_by_phone AS
SELECT phone, fio, address, bank_id, mobile_user_id, market_plece_user_id
FROM (
SELECT client_id AS mobile_client_id, phone, mobile_clients.fio AS fio, address
FROM client_calls INNER JOIN mobile_clients ON incoming_call = phone
) INNER JOIN ecosystem_mapping ON mobile_client_id = mobile_user_id;
DROP VIEW IF EXISTS answer;
CREATE VIEW answer AS
SELECT phone, contact_phone, fio, contact_fio, delivery.address, event_date
FROM info_by_phone INNER JOIN market_place_delivery AS delivery ON market_plece_user_id = user_id;
"""
# Выполнение SQL-скрипта
try:
cursor.executescript(sql_script)
conn.commit()
print("Все представления успешно созданы.")
except Exception as e:
print("Ошибка при выполнении SQL:", e)
# Выполняем запрос к финальному представлению и выводим результат
try:
query = "SELECT * FROM answer;" # можно убрать LIMIT, если нужно всё
df = pd.read_sql_query(query, conn)
print("\nРезультат запроса из представления 'answer':\n")
print(df.to_string(index=False))
except Exception as e:
print("Ошибка при выборке данных из представления 'answer':", e)
finally:
conn.close()
Вывод:
Все представления успешно созданы.
Результат запроса из представления 'answer':
phone contact_phone fio contact_fio address event_date
79297654321 79297483321 Иванов В.\,Г. Иванов В.\,Г. г. Москва, ул. Маршала Жукова, д. 7, офис 12 2020-05-07 15:21:45
79297654321 79297483321 Иванов В.\,Г. Иванов В.\,Г. г. Москва, ул. Маршала Жукова, д. 7, офис 12 2020-05-12 16:01:23
79297654321 79297483321 Иванов В.\,Г. Иванова Д.\,Е. г. Москва, Проспект мира, д. 12 кв. 175 2020-06-01 22:39:18Что делает код:
- Подключается к базе данных
bank_data.db. Выполняет SQL-скрипт, который:
- создает пять логически связанных представлений (
client_profile,client_transactions,client_calls,info_by_phone,answer); - объединяет данные из разных таблиц с помощью
INNER JOIN.
- создает пять логически связанных представлений (
- Запрашивает все строки из финального представления answer, которое содержит сведения о клиентах, их контактах и адресах доставки.
- Выводит результат запроса на экран.
- Закрывает соединение с базой данных.
Ответ на первый этап: мошенник — клиент банка Иванов В. Г., номер телефона — 79297654321, возможные адреса нахождения — г. Москва, ул. Маршала Жукова, д. 7, офис 12, г. Москва, Проспект мира, д. 12 кв. 175.
Разработанные SQL-правила поиска мошенников на этом этапе лягут в основу построения системы уведомления о подозрительных транзакциях.
На данном этапе необходимо:
- Разработать диаграмму вариантов использования для операторов колл-центра.
- Спроектировать архитектуру системы (взаимодействие базы данных, бэкенда, фронтенда, Telegram-уведомлений).
- Выбрать технологии для реализации (база данных, серверный фреймворк, UI-библиотеки, интеграция с Telegram API).
- Разработать структуру API и определить методы для обработки транзакций.
- Создать макет веб-интерфейса оператора колл-центра.
- Спроектировать механизм отправки уведомлений в Telegram на основе событий в системе.
Представленное решение является одним из возможных вариантов реализации и не претендует на статус единственно верного.
Оно иллюстрирует подход к решению задачи, но допускает альтернативные реализации, которые могут быть не менее корректными и эффективными.
Диаграмма вариантов использования (Use Case Diagram) — это диаграмма UML, которая показывает, как разные пользователи (акторы) взаимодействуют с системой через основные сценарии использования (функции). Она помогает понять, что делает система с точки зрения пользователя, а не как она устроена внутри.
Контекст: система уведомлений о подозрительных транзакциях.
Акторы (или участники) в UML-диаграммах — это внешние по отношению к системе сущности, которые взаимодействуют с ней. Это могут быть люди, другие системы или устройства, выполняющие определенные действия по отношению к системе. Проще говоря, актор — это тот, кто что-то делает с системой.
| Актор | Роль в системе |
|---|---|
| Клиент | Сообщает о подозрительной транзакции, получает уведомления и может просматривать историю |
| Оператор | Получает уведомления, просматривает инциденты, обновляет их статус |
| Аналитик | Оценивает риск, формирует отчеты, архивирует инциденты |
| Администратор | Управляет пользователями и назначает права доступа |
| Телеграм-бот | Получает уведомления, сгенерированные системой, и доставляет их пользователям |
Варианты использования (use cases) — это действия или сценарии, которые система выполняет в ответ на действия акторов (пользователей или внешних систем). Проще говоря, варианты использования — это то, что система умеет делать.
| Use Case | Описание |
|---|---|
| UC1: Сообщить о подозрительной транзакции | Клиент инициирует проверку операции |
| UC2: Получить уведомление | Клиент или оператор получает сообщение о риске |
| UC3: Просмотреть уведомления | Доступ к журналу уведомлений |
| UC4: Оценить уровень риска | Аналитик проводит предварительную оценку операции |
| UC5: Сформировать отчет по инциденту | Подробный отчет по анализу подозрительной транзакции |
| UC6: Сделать пометку в системе | Добавление служебной записи или комментария к инциденту |
| UC7: Получить данные клиента | Сбор информации о клиенте (включается в UC1) |
| UC8: Подготовить сообщение для Telegram | Формирование текста и структуры уведомления |
| UC9: Отправить уведомление в Telegram | Система отправляет сформированное сообщение в Telegram-бот |
| UC10: Обновить статус инцидента | Изменение статуса (например, «проверено», «подтверждено» и т. д.) |
| UC11: Создать нового пользователя | Администратор регистрирует нового пользователя системы |
| UC12: Назначить права доступа | Назначение ролей и уровней доступа |
| UC13: Архивировать инцидент | Перевод завершенного инцидента в архив. |
Ниже представлена текстовая структура взаимодействий между системой и ее пользователями, подготовленная для переноса в UML-диаграмму вариантов использования. Она включает в себя список акторов, основные сценарии работы системы (варианты использования) и связи между ними, что позволяет наглядно отразить функциональность проекта с точки зрения внешнего поведения.
@startuml
left to right direction
actor Клиент
actor Оператор
actor Аналитик
actor Администратор
actor "Телеграм-бот" as TelegramBot
rectangle Система {
usecase "Сообщить о подозрительной транзакции" as UC1
usecase "Получить уведомление" as UC2
usecase "Просмотреть уведомления" as UC3
usecase "Оценить уровень риска" as UC4
usecase "Сформировать отчет по инциденту" as UC5
usecase "Сделать пометку в системе" as UC6
usecase "Получить данные клиента" as UC7
usecase "Подготовить сообщение для Telegram" as UC8
usecase "Отправить уведомление в Telegram" as UC9
usecase "Обновить статус инцидента" as UC10
usecase "Создать нового пользователя" as UC11
usecase "Назначить права доступа" as UC12
usecase "Архивировать инцидент" as UC13
' include relationships
UC1 --> UC7 : <<include>>
UC4 --> UC6 : <<include>>
UC5 --> UC4 : <<include>>
UC9 --> UC8 : <<include>>
UC10 --> UC5 : <<include>>
}
Клиент --> UC1
Клиент --> UC2
Клиент --> UC3
Оператор --> UC2
Оператор --> UC3
Оператор --> UC10
Аналитик --> UC4
Аналитик --> UC5
Аналитик --> UC13
Администратор --> UC11
Администратор --> UC12
TelegramBot <-- UC9
@enduml
Данный код написан на языке разметки PlantUML — это специальный текстовый синтаксис для автоматической генерации UML-диаграмм.
Что происходит в этом коде:
@startumlи@enduml— это рамки, внутри которых находится описание диаграммы.actor— обозначает актера, т. е. внешнего пользователя системы (в данном случае: клиент, оператор, система).usecase "..." as UC#— обозначает вариант использования (что пользователь может делать в системе).–>— показывает связь между актером и вариантом использования (какое действие доступно какому пользователю).
Код применяется для создания UML-диаграмм в технической документации в инструментах вроде PlantUML online, draw.io, IntelliJ IDEA, VS Code с плагинами.
Ниже представлена диаграмма вариантов использования, оформленная по стандарту UML по описанному выше коду.
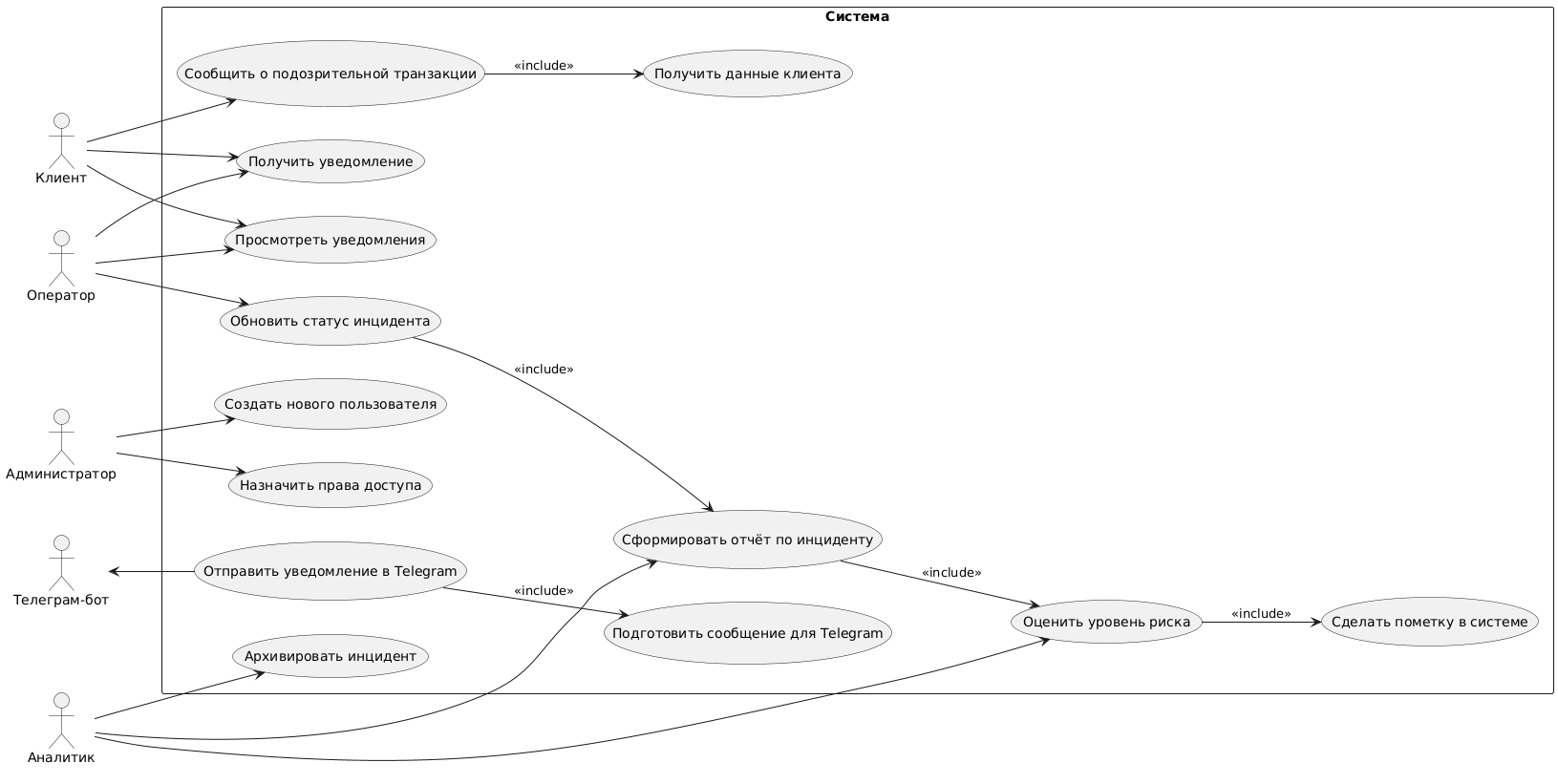
На этом шаге нужно создать архитектуру системы, которую можно описать в виде компонентной диаграммы UML (Component Diagram). Она покажет, из чего состоит система, как взаимодействуют модули, и как данные проходят между ними.
Основные элементы системы
Представим основные элементы системы, участвующие в реализации функциональности: пользовательский интерфейс, серверная логика, база данных, аналитический модуль и компонент интеграции с Telegram. Описание этих компонентов помогает понять архитектуру решения и организацию потока данных между модулями.
| Компонент | Описание |
|---|---|
| Frontend (UI) | Веб-интерфейс для оператора (просмотр уведомлений, история, фильтрация) |
| Backend (API-сервер) | Обрабатывает логику: получает данные, вызывает ML/SQL, формирует ответы |
| База данных (DB) | Хранит транзакции, клиентов, события, статусы инцидентов |
| Модуль ML/правил | Компонент анализа данных (анализ аномалий, триггеры, правила) |
| Telegram Notification Module | Отвечает за отправку сообщений в Telegram через Bot API |
Потоки данных:
- Клиент инициирует запрос (через внешнюю систему или оператор).
- Backend получает данные, передает в ML/SQL-анализ.
- Анализ формирует инцидент \(\rightarrow\) сохраняется в БД.
- Backend отправляет результат оператору через фронтенд и Telegram.
- Оператор работает через UI и может обновить статус \(\rightarrow\) снова идет запрос в backend \(\rightarrow\) БД.
Описание компонентов для UML, представленные в формате кода PlantUML
Ниже приведен текстовый шаблон архитектуры системы в формате PlantUML, который можно использовать для построения компонентной диаграммы. Он отражает ключевые модули системы — от пользовательского интерфейса до базы данных и внешних сервисов — и демонстрирует, как они взаимодействуют друг с другом в рамках решения задачи.
@startuml
package "Пользовательский интерфейс" {
[Frontend UI] as UI
}
package "Серверная логика" {
[Backend API-сервер] as BE
[Аналитический модуль (ML/триггеры)] as ML
[Модуль уведомлений Telegram] as TG
}
database "База данных" as DB
actor "Оператор" as Operator
actor "Клиент" as Client
Client --> UI : запрос (инцидент)
Operator --> UI : просмотр/действия
UI --> BE : HTTP-запрос (REST API)
BE --> DB : SQL-запросы
BE --> ML : анализ данных
ML --> BE : результат (риск)
BE --> TG : сформировать и отправить уведомление
TG --> "Telegram API"
@endumlАрхитектура системы и взаимодействие компонентов
Представим диаграмму архитектуры системы. Она показывает, как устроена система внутри: из каких частей она состоит, как они связаны между собой и как проходит поток данных — от пользователя до уведомлений в Telegram. Компонентная диаграмма поможет лучше представить, как взаимодействуют фронтенд, бэкенд, база данных, аналитика и модуль отправки уведомлений.
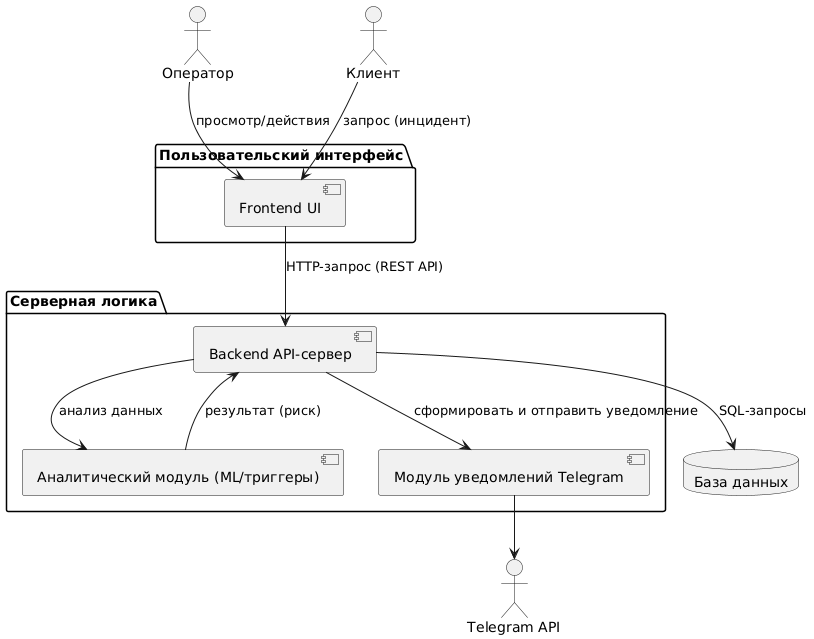
Обращаем внимание, что представленная архитектурная диаграмма — это лишь один из возможных вариантов реализации. Она отражает общее направление решения и может служить ориентиром, но не является единственно верным вариантом. У каждой команды может быть своя архитектура, в зависимости от выбранных технологий, распределения ролей и технических решений. Это соответствует духу заключительного этапа олимпиады, где ценится творческий подход, инженерное мышление и разнообразие идей.
Представляем рекомендованный стек технологий для реализации проекта с кратким обоснованием для каждой категории. Выбор технологий может варьироваться в зависимости от предпочтений и опыта команды. В таблице 1.1 представлены лишь рекомендованные инструменты, которые подходят для реализации проекта.
| Категория | Технология | Обоснование использования |
|---|---|---|
| База данных | PostgreSQL | Надежная, поддерживает сложные SQL-запросы, триггеры и связи между таблицами |
| SQLite (альтернатива) | Подходит для прототипирования и локальной разработки | |
| Бэкенд-фреймворк | FastAPI (Python) | Современный, быстрый, с автоматической документацией Swagger, идеален для REST API |
| Flask (альтернатива) | Более простой, но менее структурированный фреймворк | |
| Фронтенд (UI) | React.js | Гибкий, подходит для создания интерфейса оператора, большое сообщество и компоненты |
| Vue.js (альтернатива) | Легче в освоении, удобно для небольших проектов | |
| Интеграция Telegram | python-telegram-bot | Простая библиотека для отправки уведомлений, обработки сообщений, удобна для MVP |
| aiogram (альтернатива) | Более гибкая и асинхронная библиотека | |
| Контейнеризация | Docker | Упрощает запуск, обеспечивает одинаковую среду для всех участников |
| Работа с БД в Python | SQLAlchemy | ORM, упрощает взаимодействие с базой данных |
| ML и обработка данных | pandas, scikit-learn | Подходят для анализа транзакций и построения моделей для выявления аномалий |
В этом разделе представлена структура REST API, необходимая для взаимодействия между фронтендом, серверной частью, аналитическими модулями и системой Telegram-уведомлений. API обеспечивает доступ к данным о транзакциях, инцидентах и клиентах, а также позволяет инициировать анализ подозрительных операций и управлять уведомлениями.
Основные сущности API
Каждая сущность в API отвечает за определенный аспект системы — от работы с транзакциями до управления статусами инцидентов. Ниже перечислены ключевые сущности и их назначение.
| Сущность | Описание |
|---|---|
/transactions |
Работа с транзакциями клиентов |
/alerts |
Создание и просмотр инцидентов |
/clients |
Получение информации о клиентах |
/analyze |
Запуск аналитики по транзакциям |
/notify |
Отправка уведомлений в Telegram |
/status |
Получение и обновление статуса инцидента |
Методы и структура запросов
В данном подразделе представлены REST-методы для работы с каждой сущностью API. Все запросы формируются в формате JSON и поддерживают обработку ошибок.
| Метод | URL | Назначение |
|---|---|---|
GET |
/transactions |
Получить список транзакций |
GET |
/transactions/{id} |
Получить информацию о конкретной транзакции |
POST |
/alerts |
Зарегистрировать подозрительную операцию |
GET |
/alerts |
Получить список активных инцидентов |
POST |
/analyze |
Запустить анализ транзакции |
POST |
/telegram/notify |
Отправить уведомление в Telegram |
PATCH |
/alerts/{id}/status |
Обновить статус инцидента |
GET |
/clients/{id} |
Получить данные о клиенте |
Диаграмма взаимодействия компонентов через API
На диаграмме ниже представлен пример типового взаимодействия между оператором, пользовательским интерфейсом, API, аналитическим модулем и Telegram. Она отражает последовательность запросов и ответов, характерных для анализа подозрительной транзакции и оповещения оператора.
Представим сначала описание диаграммы на PlantUML, а далее — собственно диаграмму.
@startuml
actor Operator
participant "Frontend UI" as UI
participant "Backend API" as API
participant "ML-анализатор" as ML
participant "Telegram модуль" as TG
participant "База данных" as DB
Operator -> UI : выбирает транзакцию
UI -> API : GET /transactions/{id}
API -> DB : SQL-запрос
DB --> API : данные транзакции
API --> UI : JSON-ответ
Operator -> UI : нажимает "Анализировать"
UI -> API : POST /analyze
API -> ML : анализ
ML --> API : результат (риск высокий)
API -> TG : POST /telegram/notify
TG -> Telegram : уведомление
@enduml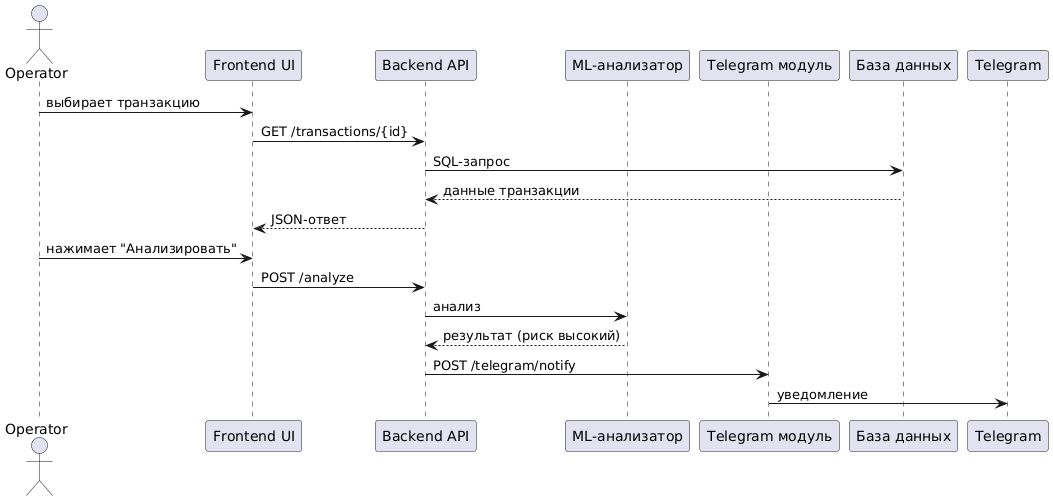
Представленная структура API и описанные сущности являются примером одного из возможных вариантов реализации. Они иллюстрируют логику взаимодействия между модулями системы, но не являются обязательными или единственно правильными. Команды могут самостоятельно определять, какие сущности использовать, как организовать маршруты и методы API, а также как структурировать обмен данными — в зависимости от выбранных архитектурных решений, распределения ролей и технического стека.
Цель этого шага — разработать макет веб-интерфейса, через который оператор сможет получать уведомления, просматривать детали инцидентов, фильтровать транзакции и обновлять их статусы.
Рекомендованный порядок действий:
- Определить пользовательские сценарии — получение уведомлений, просмотр списка инцидентов, детальный просмотр транзакции, изменение статуса (мошенничество/безопасно), фильтрация и поиск.
- Составить перечень элементов интерфейса — панель уведомлений / список инцидентов, карточка транзакции, панель фильтров (по дате, сумме, клиенту), например, кнопки: Подробнее, Подтвердить, Отклонить, Архивировать.
- Создать макет (прототип) интерфейса в графическом редакторе (например, Figma) или непосредственно в коде — HTML + CSS + JS (например, с React/Vue).
- Подготовить структуру компонентов — определить, какие данные приходят из API и как отображаются, настроить начальные состояния (пустой список, ошибка, загрузка).
- Добавить базовую интерактивность — нажатие на карточку открывает подробности, фильтры обновляют список, кнопки вызывают запросы к API.
| Компонент | Назначение |
|---|---|
Header |
Верхняя панель с названием системы, иконками, кнопкой выхода |
FilterPanel |
Панель фильтрации транзакций по различным параметрам |
IncidentList |
Главный список инцидентов, полученных из API |
AlertCard |
Отдельная карточка транзакции (краткая информация) |
IncidentDetails |
Подробная информация по инциденту и кнопки управления |
На рис. 7.4 представлен фрагмент макета веб-интерфейса в приложении Figma, разработанного командой ber, вошедшей в число победителей и призеров олимпиады. Полная версия проекта доступна на официальном сайте олимпиады НТО в разделе финальных работ. Макет иллюстрирует один из возможных вариантов реализации интерфейса оператора колл-центра.
Порядок шагов по созданию интерфейса и выбор технологий могут отличаться в зависимости от подхода и опыта каждой команды. Макет веб-интерфейса — это творческая часть решения, и каждая команда вправе реализовать его по-своему. В ходе заключительного этапа оценивается не соответствие какому-либо шаблону, а качество реализации, удобство для пользователя, логика отображения информации и общая понятность интерфейса.
На этом шаге необходимо проработать механизм отправки уведомлений в Telegram на основе событий в системе. Цель — обеспечить автоматическую отправку уведомлений операторам или администраторам через Telegram-бот, когда в системе фиксируется подозрительная транзакция или происходит важное событие.
Рекомендованный порядок действий:
Создать Telegram-бота:
перейти в Telegram \(\rightarrow\) найти @BotFather;
использовать команду
/newbot\(\rightarrow\) задать имя и получить токен.Подключить Telegram API в бэкенд: установить библиотеку
pip install python-telegram-botили использовать
requestsдля отправки HTTP-запросов вручную.Определить события для уведомлений:
пример: выявлена подозрительная транзакция, изменение статуса инцидента, отклонение оператором и т. д.
Создать обработчик событий на сервере:
в коде бэкенда прописать логику: если событие
Xпроизошло \(\rightarrow\) вызвать функциюsend_telegram_message().Сформировать текст уведомления:
включить ключевые параметры: ID транзакции, клиент, сумма, уровень риска, ссылка на интерфейс.
Отправить уведомление оператору:
передать сообщение через Telegram Bot API \(\rightarrow\) в чат или в группу.
Рекомендуемые технологии для построения механизма отправки уведомлений в Telegram представлены в таблице 1.2.
| Назначение | Технология |
|---|---|
| Интеграция с Telegram | python-telegram-bot, aiogram, requests |
| События в системе | Сигналы/триггеры в backend (FastAPI/Flask) |
| Очереди (опц.) | Celery, Redis (если нагрузка большая) |
Пример схемы взаимодействия компонентов механизма отправки уведомлений в Telegram приведен ниже.
Представим сначала описание схемы взаимодействия компонентов на PlantUML, а далее — собственно схему.
@startuml
actor Backend
participant "Trigger / Event System"
participant "Telegram Notification Module"
participant "Telegram API"
Backend -> "Trigger / Event System" : фиксирует событие
"Trigger / Event System" -> "Telegram Notification Module" : вызывает отправку уведомления
"Telegram Notification Module" -> "Telegram API" : HTTP-запрос с сообщением
Telegram API --> "Telegram Notification Module" : статус 200 OK
@enduml
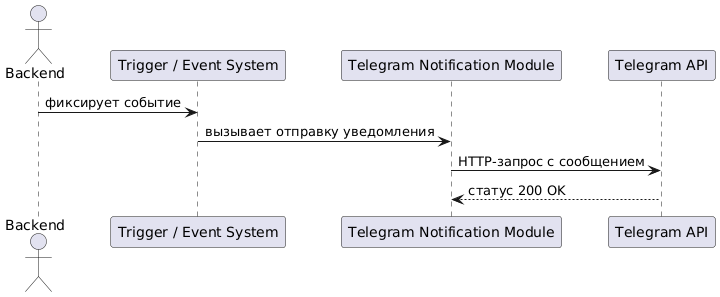
Команды могут реализовать механизм уведомлений по-разному — использовать асинхронную отправку, очереди или даже webhooks (способ, с помощью которого одна система может автоматически отправлять уведомление другой системе, когда происходит определенное событие). Главное — чтобы уведомление формировалось по событию и доставлялось оперативно и информативно.
Для своевременного обнаружения потенциально мошеннических действий система должна обладать встроенными механизмами реагирования на аномальные транзакции. Такие механизмы могут быть реализованы в виде триггеров, наборов бизнес-правил, а также моделей машинного обучения. Выбор подхода зависит от целей проекта, доступных данных и глубины решения. В основу этого шага ложится ваша работа первого этапа.
Пример 1: бизнес-правила и триггеры
Один из распространенных способов — задание четких правил, по которым система автоматически помечает транзакции как подозрительные. Такие правила можно реализовать как на уровне базы данных (SQL), так и в серверной логике (Python, Java и др.).
Примеры правил:
- сумма перевода превышает 500000 руб;
- клиент совершает более двух переводов за 1 мин;
- переводы на одни и те же счета из разных городов;
- транзакция происходит ночью при отсутствии активности днем.
Реализация может включать:
- SQL-триггеры на события
INSERTилиUPDATE(реакция на событие обновления); - Python-функции, реагирующие на поступление данных;
- отправку уведомления через Telegram при срабатывании правила.
Пример 2: использование машинного обучения
Более продвинутый вариант — построение ML-модели для анализа аномалий в транзакциях. Такой подход позволяет учитывать скрытые зависимости и паттерны поведения, которые сложно формализовать вручную.
Что можно сделать:
- построить классификатор на основе обучающей выборки (например,
Random Forest); - использовать алгоритмы аномалий (
Isolation Forest,OneClassSVM); - обучить модель на временных рядах активности клиента;
- построить граф аффилированных клиентов и находить кластеры.
Для обучения могут использоваться признаки:
- время;
- сумма;
- частота;
- география переводов;
- идентификаторы получателей;
- история обращений или жалоб.
Упрощенная схема взаимодействия бизнес-правил и алгоритмов ML
Представим сначала описание схемы взаимодействия бизнес-правил и алгоритмов ML на PlantUML, а далее — собственно схему.
@startuml
actor "Клиент"
participant "Backend"
participant "ML / Бизнес-правила"
database "База данных"
participant "Telegram Модуль"
"Клиент" -> "Backend" : инициирует транзакцию
"Backend" -> "ML / Бизнес-правила" : анализирует данные
"ML / Бизнес-правила" --> "Backend" : возвращает статус
"Backend" --> "База данных" : записывает результат
"Backend" -> "Telegram Модуль" : отправляет уведомление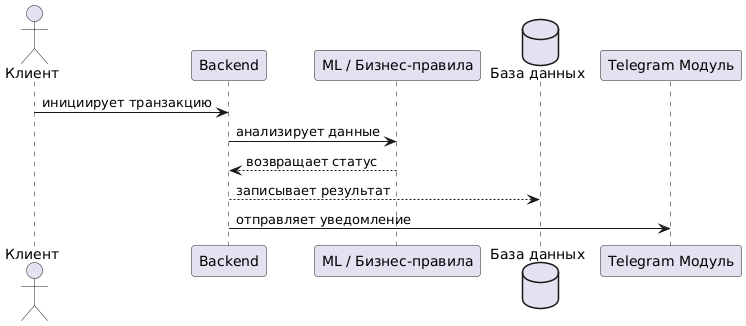
Каждая команда самостоятельно выбирает подход к реализации механизма выявления подозрительных операций, и это — одна из точек различия в решениях. В рамках оценки учитывается, насколько продуман и обоснован выбранный подход.
На базовом уровне рассматриваются простые условия, например, превышение заданного порога суммы транзакции или превышение количества операций за короткий период. Более продвинутые решения включают разработку набора бизнес-правил или триггеров, например, срабатывание при переводах на один счет с разных устройств, при ночной активности без дневной или при частом повторении операций между одними и теми же клиентами.
Наиболее комплексные подходы предусматривают использование алгоритмов машинного обучения — команды предлагают применение моделей для выявления аномалий, таких как:
- классификация операций;
- построение поведенческого профиля клиента;
- кластеризация;
- графовые модели;
- работа с временными рядами.
В этих случаях также оценивается наличие перечня признаков (features), описание выбранного метода (например, Random Forest, Isolation Forest) и обоснование параметров модели. Критерием является не наличие кода, а детальность проработки подхода — насколько реализация связана с анализом и пониманием сути проблемы.
Документация по архитектуре проекта помогает понять, как устроена система, какие модули в ней присутствуют и как они взаимодействуют друг с другом. Она особенно важна, когда систему разрабатывает команда и требуется согласованное понимание ее структуры. Архитектурная документация могла быть представлена участниками в свободной форме — от краткого описания до полноценного технического отчета с диаграммами, списками компонентов, маршрутами API и технологиями.
Что рекомендовано включать в архитектурную документацию:
- описание основных компонентов (фронтенд, бэкенд, БД, ML-модуль, Telegram-модуль);
- схемы взаимодействия между ними (например, в формате PlantUML);
- примеры запросов (если есть API);
- обоснование выбора технологий;
- визуализация архитектуры в виде диаграммы компонентов или последовательности.
Пример краткого описания архитектуры
Система состоит из frontend-интерфейса, backend-сервера на FastAPI, базы данных PostgreSQL и модуля отправки уведомлений в Telegram. Интерфейс обращается к REST API, который взаимодействует с БД и по заданным условиям отправляет уведомления через Telegram Bot API.
Пример структурированной архитектурной документации
Архитектура проекта
Технологии:
- Backend: FastAPI (Python).
- Frontend: React.
- База данных: PostgreSQL.
- Уведомления: python-telegram-bot.
Компоненты:
- client-ui: веб-интерфейс оператора, реализован на React, получает данные через REST API.
- incident-api: обрабатывает обращения, проверяет транзакции, передает результат в ML-модуль.
- ml-analyzer: модуль анализа транзакций на основе обученной модели.
- tg-sender: микросервис отправки сообщений в Telegram.
Схема взаимодействия:
- вставлена диаграмма UML.
Дополнительно:
- API описан в Swagger.
- Настройка окружения через docker-compose.
- Все модули документированы в формате Markdown.
Команды имеют свободу в оформлении архитектурной документации — от простого описания в файле README.md до полноценного отчета. В рамках оценки учитывается, представлена ли документация вообще, носит ли она краткий и общий характер, или содержит четкую структуру, примеры, визуализации и технические детали. Кроме того, оценивается оформление в читаемом и практичном формате (Markdown, PDF, DOCX).
Система уведомлений и анализа транзакций может использоваться как в прототипе, так и в более масштабной промышленной версии. При росте нагрузки, увеличении объема данных или числа пользователей необходимо предусмотреть архитектурные решения, обеспечивающие устойчивость, производительность и гибкость. На этом шаге представлены возможные направления масштабирования системы (таблица 1.3).
| Направление | Описание |
|---|---|
| Микросервисная архитектура | Разделение системы на независимые компоненты (API, ML, Telegram и др.) для гибкой поддержки и масштабирования |
| Очереди сообщений | Использование брокеров (RabbitMQ, Redis, Kafka) для асинхронной обработки событий и разгрузки API |
| Горизонтальное масштабирование | Развертывание компонентов на нескольких серверах или контейнерах для увеличения производительности |
| Вертикальное масштабирование | Увеличение вычислительных ресурсов сервера (CPU, RAM) при начальной нагрузке |
| Кеширование | Использование кеша (например, Redis) для хранения часто запрашиваемых данных и ускорения работы |
| Репликация и шардирование БД | Повышение надежности и масштабируемости хранения данных за счет распределения и копирования |
Представим схему масштабируемой архитектуры (в PlantUML).
@startuml
node "API Gateway" {
[Frontend UI]
}
node "Backend Services" {
[Аналитика (ML)]
[Telegram Sender]
[Инциденты API]
}
database "Основная база данных" as DB
queue "Очередь сообщений (RabbitMQ)" as MQ
[Frontend UI] --> [API Gateway]
[API Gateway] --> [Инциденты API]
[Инциденты API] --> DB
[Инциденты API] --> MQ
MQ --> [Telegram Sender]
MQ --> [Аналитика (ML)]
@enduml
Построим диаграмму по этому коду.
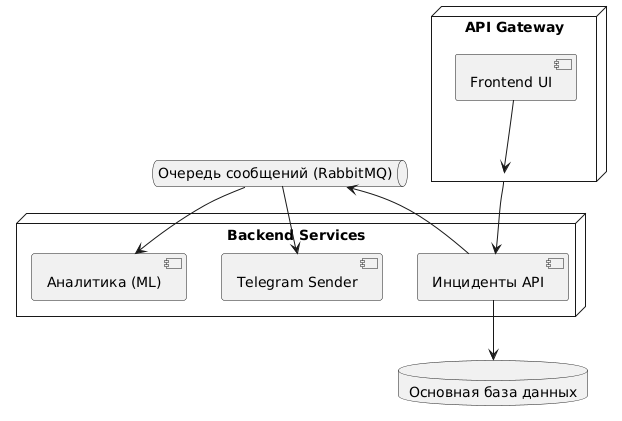
Представленные подходы — лишь один из вариантов развития архитектуры. Каждая команда может предложить собственное решение масштабирования: будь то переход на микросервисную архитектуру, внедрение очередей сообщений или оптимизация хранения и обработки данных. В ходе оценки учитывались именно предложенные команды механизмы масштабирования, а не строгость их реализации.
На этом этапе участники переходят от проектирования к полноценной реализации системы. Основная задача — воплотить разработанную архитектуру в виде работающего программного решения: написать код, реализовать интерфейсы, настроить взаимодействие между компонентами и убедиться, что система корректно реагирует на события (например, подозрительные транзакции).
Система должна быть протестирована, запускаться без ошибок и демонстрировать реакцию на изменения в базе данных или пользовательские действия. Реализация включает бэкенд, фронтенд, API, Telegram-интеграцию, алгоритмы анализа данных и базовую визуализацию.
В рамках этого методического пособия этап реализации проекта будет описан в виде двух последовательных шагов:
- реализация компонентов — включает описание создания бэкенда, интерфейса, API, интеграции с Telegram и алгоритмов обработки данных;
- код и документация — содержит требования к качеству кода и инструкции по запуску проекта.
Далее приводятся фрагменты решений команд, вошедших в число победителей и призеров олимпиады чьи решения получили высокие оценки. Они могут служить иллюстрацией ключевых шагов реализации проекта, подходов к решению задач и особенностей архитектуры, использованных участниками.
Реализация бэкенда с использованием фреймворка
Участники могут выбрать любой современный серверный фреймворк (FastAPI, Flask, Django, Express и т. д.) для построения API, обработки логики анализа и работы с базой данных.
В качестве примера ниже представлен фрагмент кода с использованием фреймворка Django (от участников команды Naumov22, которая входит в число победителей и призеров профиля).
from django.contrib import admin
from .models import FraudAnalysisResult
@admin.register(FraudAnalysisResult)
class FraudAnalysisResultAdmin(admin.ModelAdmin):
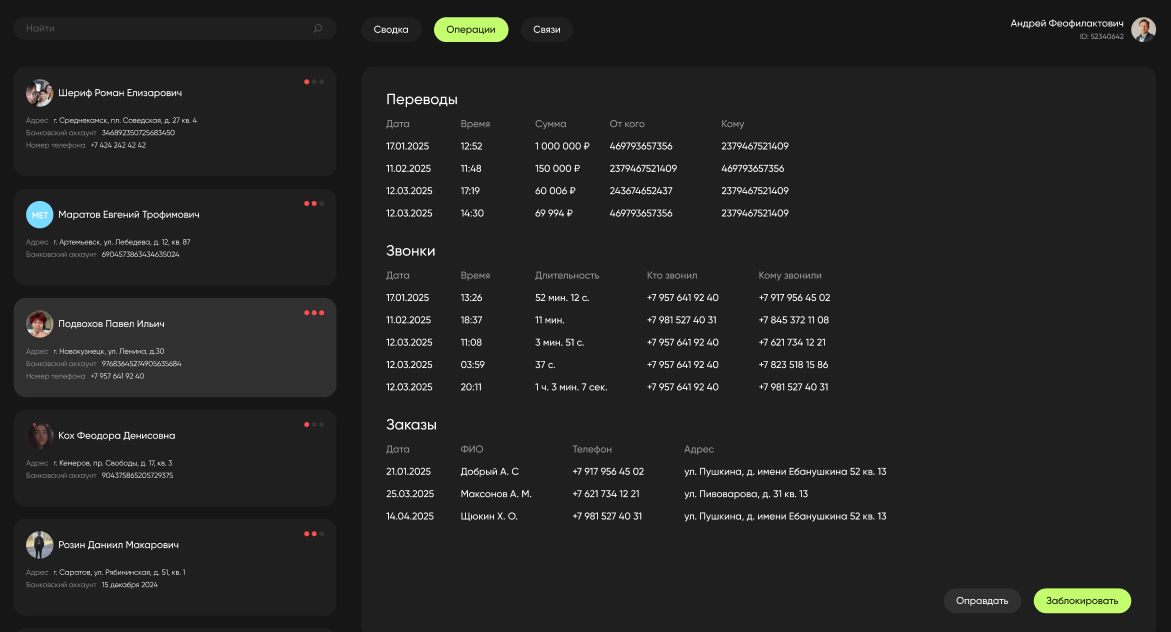
list_display = ('identifier', 'reason', 'id_type', 'fio', 'phone', 'address', 'mobile_id', 'marketplace_id')
list_filter = ('reason', 'id_type', 'identifier')
search_fields = ('identifier', 'reason', 'id_type')Этот код регистрирует модель FraudAnalysisResult в административной панели Django и настраивает, как она будет отображаться в интерфейсе администратора. Импортируются модуль admin и модель FraudAnalysisResult, которая описывает результаты анализа подозрительных операций. Регистрирует модель в админке и связывает ее с классом настройки FraudAnalysisResultAdmin декоратор @admin.register(...). list_display определяет столбцы, которые будут показаны в списке записей на странице модели. list_filter добавляет фильтры справа в интерфейсе администратора — для удобной фильтрации записей по указанным полям. search_fields позволяет осуществлять поиск по этим полям в строке поиска вверху интерфейса администратора.
В качестве примера ниже представлен фрагмент кода с использованием фреймворка Django (от участников команды Naumov22, которая входит в число победителей и призеров профиля).
from django.db import models
class FraudAnalysisResult(models.Model):
identifier = models.CharField("Идентификатор", max_length=255)
reason = models.CharField("Причина подозрения", max_length=255)
id_type = models.CharField("Тип идентификатора", max_length=50, blank=True)
created_at = models.DateTimeField("Когда проанализировано", auto_now_add=True)
fio = models.CharField(max_length=255, blank=True)
phone = models.CharField(max_length=50, blank=True)
address = models.TextField(blank=True)
mobile_id = models.CharField(max_length=100, blank=True)
marketplace_id = models.CharField(max_length=100, blank=True)
def __str__(self):
return f"{self.identifier} — {self.reason}"
Данный код определяет модель FraudAnalysisResult в рамках фреймворка Django, предназначенную для хранения информации о результатах анализа подозрительных транзакций. Модель содержит поля для идентификатора объекта (identifier), причины, по которой он был признан подозрительным (reason), типа идентификатора (id_type), а также времени создания записи (created_at).
Дополнительно предусмотрены поля для хранения персональных данных, таких как Ф. И. О., номер телефона, адрес, а также идентификаторов мобильного пользователя и пользователя маркетплейса. Метод __str__ определяет строковое представление экземпляра модели, которое используется в интерфейсах отображения и логирования. Эта модель будет отображаться в базе данных как таблица и может использоваться для обработки, хранения и анализа результатов в рамках приложения.
Реализация веб-интерфейса оператора
Интерфейс должен позволять оператору видеть список инцидентов, фильтровать данные, просматривать детали транзакций и управлять их статусом. Использование фреймворков (React, Vue, Bootstrap и др.) приветствуется.
Пример кода интерфейса на фреймфорке Vue (файл DashboardView.vue, фрагмент кода команды «Троичный код», которая входит в число победителей и призеров профиля), представлен ниже.
<template>
<main class="col-md-9 ms-sm-auto col-lg-10 px-md-4">
<div class="d-flex justify-content-between flex-wrap flex-md-nowrap align-items-center pt-3 pb-2 mb-3 border-bottom">
<h1 class="h2">Dashboard</h1>
<div class="btn-toolbar mb-2 mb-md-0 buttons">
<button type="button" class="btn btn-sm btn-outline-secondary dropdown-toggle d-flex align-items-center gap-1">
<svg class="bi" aria-hidden="true"><use xlink:href="#calendar3"></use></svg>
Эта неделя
</button>
</div>
</div>
<canvas class="my-4 w-100" id="myChart" width="100%" height="" style="display: block; box-sizing: border-box; height: 440px; width: 1042px;"></canvas>
<h2>Заголовок секции</h2>
<div class="table-responsive small">
<table class="table table-striped table-sm">
<thead>
<tr>
<th scope="col">Количество транзакций</th>
<th scope="col">Количество мошеннических транзакций</th>
<th scope="col">Сумма украденных денег</th>
</tr>
</thead>
<tbody>
<tr>
<td>{{ dashboard_data.txns_count }}</td>
<td>{{ dashboard_data.fraud_txns_count }}</td>
<td>{{ dashboard_data.stolen_money }}</td>
</tr>
</tbody>
</table>
</div>
</main>
</template>
<style>
.buttons button{
height: 100px;
}
</style>
Этот код представляет собой шаблон Vue-компонента, реализующего основное содержимое панели управления (Dashboard) веб-приложения, предназначенного для мониторинга подозрительных транзакций. Разметка использует классы Bootstrap для стилизации и адаптивного расположения элементов.
В верхней части отображается заголовок Dashboard и кнопка с выпадающим меню, обозначающая текущий временной диапазон («Эта неделя»). Ниже размещен график (<canvas id="myChart">), предназначенный для визуализации статистики, например, числа транзакций по дням или уровня риска — предполагается, что график будет построен с использованием библиотеки Chart.js или аналогичной.
Под графиком размещена таблица с заголовком «Заголовок секции», содержащая три ключевых показателя:
- общее количество транзакций;
- количество выявленных мошеннических транзакций;
- общая сумма украденных средств.
Эти значения динамически подставляются из объекта dashboard_data, который, вероятно, поступает из API или хранилища данных (Vuex, Pinia и др.). Таким образом, компонент визуализирует ключевые метрики и предоставляет оператору колл-центра или аналитику общее представление о текущей ситуации с мошенническими операциями в системе.
Интеграция с Telegram
Система должна уметь автоматически отправлять уведомления через Telegram при срабатывании правил или алгоритма. Интеграция может быть реализована через Telegram Bot API.
Пример функции отправки сообщения в Телеграм (фрагмент кода от участников команды Naumov22, которая входит в число победителей и призеров профиля) представлен ниже.
def send_report_via_telegram(report_text):
url = f"https://api.telegram.org/bot{BOT_TOKEN}/sendMessage"
for chat_id in CHAT_IDS:
print(f"!!!!!ЗДЕСЬ Отправка отчёта пользователю {chat_id}...")
for i in range(0, len(report_text), 4000): # Telegram ограничение
chunk = report_text[i:i + 4000]
requests.post(url, data={"chat_id": chat_id, "text": chunk})
printf(f"Отправлено пользователю {char_id}")Этот код реализует функцию отправки текстового отчета в Telegram нескольким получателям. Функция send_report_via_telegram(report_text) принимает текст отчета и для каждого идентификатора чата из списка CHAT_IDS отправляет его через Telegram Bot API.
Поскольку Telegram ограничивает длину одного сообщения 4096 символами, текст предварительно разбивается на части по 4000 символов, чтобы избежать ошибок при передаче. Каждая часть отправляется отдельно с помощью POST-запроса на API-адрес, сформированный с использованием токена бота BOT_TOKEN. В процессе выполнения выводятся сообщения о начале и завершении отправки для каждого пользователя.
Реализация алгоритмов и триггеров
Расширенная реализация может включать машинное обучение или продвинутые SQL/логические триггеры для анализа транзакций и генерации инцидентов.
Пример кода детектора аномалий с использование алгоритмов машинного обучения (фрагмент кода от участников команды Naumov22, которая входит в число победителей и призеров профиля) представлен ниже.
# detect_suspicious_by_model.py
import pandas as pd
import sqlite3
import joblib
# Загрузка обученной модели
print("ℹ Описание признаков:")
print("Признак 1 — номер получателя доставки используется более чем у 3 клиентов за 1 час")
print("Признак 2 — первый перевод на сумму больше 10 000 рублей")
print("Признак 3 — после звонка был перевод в течение 1–10 минут")
print("Признак 4 — перевод ночью (с 22:00 до 06:00)")
print("Признак 5 — получатель получил переводы от более чем 3 разных клиентов за 1 час")
print("")
model = joblib.load("fraud_model.pkl")
# Подключение к базе
import argparse
parser = argparse.ArgumentParser(description="???? Проверка транзакций через обученную модель")
parser.add_argument("--db", type=str, default="anti_fraud_ml.db", help="Путь к SQLite базе данных")
args = parser.parse_args()
DB_PATH = args.db
conn = sqlite3.connect(DB_PATH)
bank_clients = pd.read_sql("SELECT * FROM bank_clients", conn)
bank_transactions = pd.read_sql("SELECT * FROM bank_transactions", conn)
mobile_build = pd.read_sql("SELECT * FROM mobile_build", conn)
ecosystem_mapping = pd.read_sql("SELECT * FROM ecosystem_mapping", conn)
market_place = pd.read_sql("SELECT * FROM market_place_delivery", conn)
bank_transactions['event_date'] = pd.to_datetime(bank_transactions['event_date'])
mobile_build['event_date'] = pd.to_datetime(mobile_build['event_date'])
market_place['event_date'] = pd.to_datetime(market_place['event_date'])
# Подготовка индексов
acc_to_user = bank_clients.set_index('accout')['userId'].to_dict()
user_to_id = ecosystem_mapping.set_index('bank_id')['id'].to_dict()
acc_to_phone = bank_clients.set_index('accout')['phone'].to_dict()
# Создание признаков для всех id
print("???? Формируем признаки для модели...")
features = []
for _, eco in ecosystem_mapping.iterrows():
eid = eco['id']
bank_id = eco['bank_id']
if not bank_id:
continue
accs = bank_clients[bank_clients['userId'] == bank_id]['accout'].tolist()
phones = bank_clients[bank_clients['userId'] == bank_id]['phone'].tolist()
f = {
'id': eid,
'is_phone_shared': 0,
'is_first_large_transfer': 0,
'is_call_before_transfer': 0,
'is_night_transfer': 0,
'is_many_senders': 0
}
# Признак 1: номер доставки встречается у >3 пользователей в 1 час
mpd_rows = market_place[market_place['user_id'] == eco['market_plece_user_id']]
if not mpd_rows.empty:
for _, row in mpd_rows.iterrows():
block = market_place[(market_place['contact_phone'] == row['contact_phone']) & (market_place['event_date'].dt.floor('h') == row['event_date'].floor('h'))]
if block['user_id'].nunique() > 3:
f['is_phone_shared'] = 1
break
# Признак 2: первый перевод > 10_000
user_acc = accs[0] if accs else None
if user_acc:
txs = bank_transactions[bank_transactions['account_in'] == user_acc]
if not txs.empty:
first = txs.sort_values('event_date').iloc[0]
if first['value'] > 10_000:
f['is_first_large_transfer'] = 1
# Признак 3: звонок → перевод через 1–10 минут
if phones:
for phone in phones:
calls = mobile_build[mobile_build['to_call'] == phone]
for _, call in calls.iterrows():
after = call['event_date'] + pd.Timedelta(minutes=1)
before = call['event_date'] + pd.Timedelta(minutes=10)
txs = bank_transactions[
(bank_transactions['account_out'].isin(accs)) &
(bank_transactions['event_date'] >= after) &
(bank_transactions['event_date'] <= before)
]
if not txs.empty:
f['is_call_before_transfer'] = 1
break
# Признак 4: перевод ночью
night = bank_transactions[(bank_transactions['account_in'].isin(accs)) &
((bank_transactions['event_date'].dt.hour < 6) |
(bank_transactions['event_date'].dt.hour >= 22))]
if not night.empty:
f['is_night_transfer'] = 1
# Признак 5: >3 разных отправителя за 1 час
txs = bank_transactions[bank_transactions['account_in'].isin(accs)].copy()
txs['hour'] = txs['event_date'].dt.floor('h')
grouped = txs.groupby(['hour'])['account_out'].nunique().reset_index()
if any(grouped['account_out'] > 3):
f['is_many_senders'] = 1
features.append(f)
# Предсказание
print("???? Предсказание модели...")
df_features = pd.DataFrame(features)
X = df_features.drop(columns=['id'])
df_features['predicted_fraud'] = model.predict(X)
# Вывод
print("\n???? Результаты модели:")
suspects = df_features[df_features['predicted_fraud'] == 1].copy()
suspects['fraud_score'] = model.predict_proba(X[df_features['predicted_fraud'] == 1])[:, 1]
suspects = suspects.sort_values(by='fraud_score', ascending=False)
for _, row in suspects.iterrows():
reasons = []
if row['is_phone_shared']: reasons.append("Признак 1")
if row['is_first_large_transfer']: reasons.append("Признак 2")
if row['is_call_before_transfer']: reasons.append("Признак 3")
if row['is_night_transfer']: reasons.append("Признак 4")
if row['is_many_senders']: reasons.append("Признак 5")
print(f"ID {row['id']}: модель предсказала фрод (вероятность: {row['fraud_score']:.2f}) → {', '.join(reasons)}")
Этот скрипт detect_suspicious_by_model.py реализует автоматическую проверку пользователей на предмет возможного мошенничества с использованием ранее обученной модели машинного обучения.
Он загружает модель из файла fraud_model.pkl и применяет ее к данным, извлеченным из базы SQLite, путь к которой можно передать через аргумент –db.
Скрипт подключается к базе данных и извлекает таблицы с транзакциями, клиентами, звонками, сопоставлением ID и доставками. Затем для каждого пользователя формируются признаки (features), отражающие подозрительные шаблоны поведения:
- Один и тот же номер телефона доставки используется более, чем у трех клиентов в течение одного часа.
- Первый перевод пользователя превышает 10000 руб.
- После звонка клиент совершает перевод в течение 1–10 мин.
- Перевод был совершен ночью (с 22:00 до 6:00).
- Один получатель получает переводы от более чем трех разных отправителей в течение одного часа.
После генерации признаков скрипт передает их в обученную модель, которая делает предсказание о том, является ли поведение пользователя подозрительным. Для пользователей, помеченных как потенциальные мошенники (предсказание = 1), также вычисляется оценка уверенности модели (fraud score).
В конце скрипт выводит в консоль список ID подозрительных пользователей, вероятности мошенничества и список сработавших признаков, благодаря которым модель приняла такое решение. Таким образом, скрипт автоматизирует процесс анализа поведения клиентов и может использоваться для поддержки операторов и аналитиков в задачах поиска и прогнозирования мошенничества.
Шаг 2. Код и документация
Качественный код и понятная документация — неотъемлемая часть любого инженерного проекта. В условиях командной олимпиады это особенно важно: эксперты оценивают не только работоспособность системы, но и насколько легко ее прочитать, воспроизвести и доработать. Хорошо оформленный код и наличие инструкций по запуску проекта помогают быстро протестировать решение в едином окружении и убедиться в его корректности.
| Категория | Требования |
|---|---|
| Читаемость | Используйте понятные имена переменных и функций. Разделяйте код на логические блоки и модули. |
| Структура проекта | Разделяйте проект на модули (frontend/backend), упорядочивайте файловую структуру проекта. |
| Стиль кода | Избегайте дублирования кода (принцип DRY). Придерживайтесь единого стиля: отступы, длина строк, соглашения по наименованию. Рекомендуемые гайды: PEP8 (Python): https://peps.python.org/pep-0008/. JavaScript Style Guide (Airbnb): https://github.com/airbnb/javascript. Google Java Style Guide: https://google.github.io/styleguide/javaguide.html. |
| Комментирование | Добавляйте комментарии к ключевым фрагментам кода, особенно если логика неочевидна. Используйте docstring в функциях и классах (Python). Подпишите нестандартные настройки, параметры, переменные. |
Проект должен содержать файл README.md или аналог, в котором описано:
- что именно делает проект;
- указано, как его запустить;
- перечислены зависимости и способы их установки;
- приведен пример использования или тестирования;
- по возможности — указаны команды для запуска через Docker (если используется).
Пример содержимого файла README.md (из документации проекта команды ber, которая входит в число победителей и призеров профиля) представлен ниже.
### Автоматическое создание таблиц
Когда в файле `.env` установлено значение `NODE_ENV=development`, при запуске бэкенда таблицы в базе данных создаются автоматически с использованием ORM. Если значение `NODE_ENV` будет отличаться от `development` (например, `production`), автоматическое создание таблиц не выполняется, и их нужно будет создать вручную.
### Создание администратора
Для создания администратора в системе выполните следующую команду:
```bash
pnpm db:create-admin
```
Или с передачей логина и пароля в качестве аргументов:
```bash
pnpm db:create-admin admin securepassword
```
Если логин и пароль не указаны в аргументах, скрипт запросит их во время выполнения.
### Заполнение базы данных тестовыми данными
Мы дополнили стандартный датасет небольшим количеством собственных данных для более полной демонстрации функционала. Если вы хотите протестировать сервис только с исходными данными, переименуйте директорию `apps/migrations/samples-old` в `apps/migrations/samples`.
Для заполнения базы данных тестовыми данными выполните:
```bash
pnpm db:insert-defaults
```
**Важно**: Перед запуском скриптов создания администратора и заполнения базы убедитесь, что:
1. Бекенд был запущен хотя бы один раз в режиме разработки для создания необходимых таблиц в базе данных
2. База данных настроена и доступна по URL, указанному в .env файлеФрагмент документации команды ber оформлен грамотно и соответствует требованиям к технической документации. Информация логично структурирована по смысловым блокам, команды снабжены пояснениями, язык изложения простой и понятный. Пошаговое описание процесса создания администратора и заполнения базы данных позволяет быстро воспроизвести действия даже тем, кто не знаком с проектом. Хорошо, что сделан акцент на важных условиях запуска, например, необходимости запуска бэкенда в режиме разработки до выполнения скриптов — это предотвращает типичные ошибки.
В качестве небольшого улучшения можно было бы добавить шаблон .env и пояснение по структуре переменных окружения, чтобы пользователь сразу понимал, где и как указать путь к базе. Кроме того, было бы полезно добавить краткое описание, содержащее информацию о том, как проверить успешность действий (например, через вход в интерфейс администратора). Тем не менее данный фрагмент является одним из лучших примеров качественной документации среди команд и существенно упрощает процесс тестирования и запуска проекта.
Например, проект команды «Троичный код» имеет хорошо организованную и логичную файловую структуру. Есть разделение по каталогам, и оно соответствует основным компонентам системы: отдельно выделены папки для фронтенда и бэкенда с указанием используемых фреймворков, присутствует отдельный модуль для Telegram-бота, а также блок, связанный с реализацией машинного обучения. Благодаря такому подходу легко ориентироваться в проекте, понимать назначение каждого элемента и находить нужные файлы. Команда включила в проект файл README.md с инструкциями запуска. Эта структура является одной из лучших среди представленных решений финала, это отличный пример оформления проекта.
Пример файловой структуры проекта команды «Троичный код», которая входит в число победителей и призеров профиля, приведен на рисунке 7.8.
Заключение
Каждая команда реализует проект в соответствии со своей архитектурой, возможностями и выбором технологий. Оценка проводится не по единообразию решений, а по фактической работоспособности системы, качеству реализации, наличию связей между модулями, поддержке уведомлений, фильтрации данных и оформлению проекта.
Кроме того, каждая команда представляет видеозапись демонстрации проекта — это дает возможность всем участникам подробно рассказать о том, что было ими сделано, показать запуск системы, объяснить особенности реализации и подтвердить авторство решения.
Участники успешно демонстрируют работу полноценной системы по отправке уведомлений и анализу подозрительных транзакций, решив задачу, поставленную партнером профиля — ПАО Сбербанк (https://sberstudent.ru/). Лучшие команды отмечаются наградами от организаторов и партнера профиля.
- Python и основы разработки на Python. Официальная документация. URL: https://docs.python.org/3/.
- Stepik: Программирование на Python. URL: https://stepik.org/course/67.
- Основы работы с базами данных и SQL. Бесплатный курс, Яндекс Практикум. URL: https://start.practicum.yandex/sql-database-basics.
- PostgreSQL. Официальная документация. URL: https://www.postgresql.org/docs/.
- Mode SQL Tutorial — практикум на английском языке. URL: https://mode.com/sql-tutorial/.
- FastAPI. Официальная документация. URL: https://fastapi.tiangolo.com/.
- Stepik: Веб-разработка на Flask. URL: https://stepik.org/course/512.
- Telegram Bot API. Официальная документация. URL: https://core.telegram.org/bots/api.
- Создание Telegram-бота на Python / Habrahabr. URL: https://habr.com/ru/post/262247/.
- REST API — простое объяснение / Habrahabr. URL: https://habr.com/ru/articles/590679/.
- Swagger / OpenAPI Docs. URL: https://swagger.io/docs/.
- The Twelve-Factor App. URL: https://12factor.net/ru/.
- Diagrams.net (draw.io) — инструмент для создания схем. URL: https://app.diagrams.net/.
- UML Use Case Diagrams — Lucidchart Guide. URL: https://www.lucidchart.com/pages/uml-use-case-diagram.
- Git Handbook / GitHub Guides. URL: https://guides.github.com/introduction/git-handbook/.
- Stepik: Git + GitHub. URL: https://stepik.org/course/3145.
- Введение в Data Science и машинное обучение. Stepik. URL: https://stepik.org/course/62243/promo.
- Scikit-learn. Руководство пользователя. URL: https://scikit-learn.org/stable/user_guide.html.





