
Инженерный тур. 2 этап
В рамках второго этапа участникам предстоит решить комплекс задач, направленных на демонстрацию навыков программирования, работы с данными и базами данных в контексте финансового менеджмента. Для их выполнения необходимо использовать язык программирования Python, современные подходы к обработке данных и разработке программных решений, актуальных для финансовой отрасли.
Давайте знакомиться! Ваш спутник на этом этапе Олимпиады — ученик старшей школы Георгий. Любимый мультяшный персонаж из глубокого детства Георгия — Дядя Скрудж, который, благодаря своему усердию и умению обращаться с деньгами, стал самым богатым утенком на свете. И Георгий убежден, что может так же — заработать и накопить достаточно денег, чтобы осуществить свои самые смелые мечты.
Вдохновленный примерами успешных утят и некоторых не менее успешных людей, Георгий выбрал одну из самых перспективных профессий — программист. Он слышал, что хорошие программисты получают высокие зарплаты, а отличные программисты — еще больше. Каждый день он усердно учился, изучал языки программирования и решал сложные задачи, мечтая о том, как однажды сможет стать мастером своего дела и, возможно, превзойти даже Дядю Скруджа в умении управлять финансами.
Еще Георгий знает: чтобы стать богатым, нужно не только зарабатывать, но и уметь грамотно распоряжаться деньгами. Для достижения поставленной цели Георгий решил внимательно относиться и к личным расходам и доходам, и к расходам и доходам семьи. Он начал вести дневник, в котором записывал все свои траты на продукты, развлечения, транспорт и другие нужды. Помогите Георгию справиться с задачами второго этапа и подготовиться к заключительному. И, кто знает, возможно, однажды вы вместе с Георгием станете не только богатыми, но и мудрыми, как его кумиры.
Предположим, Георгий решил открыть вклад в банке на некую сумму в рублях под определенный процент годовых с капитализацией процентов. Проценты начисляются ежеквартально. Важно также, на какой период времени в годах открыт вклад. Напишите функцию для расчета итоговой суммы вклада по окончании срока с учетом капитализации процентов. На вход функции должны подаваться следующие данные:
- начальная сумма вклада;
- процентная ставка (в процентах);
- срок вклада в годах.
Для написания функции необходимо использовать язык программирования Python. Для того чтобы ответ был засчитан корректно, функция должна выводить только целую часть числа без округления (!).
Для расчета итоговой суммы по вкладу с капитализацией используется формула сложного процента: \[S = P \cdot \left(1 + \frac{r}{m}\right)^{m \cdot n},\] где
- \(S\) — итоговая сумма;
- \(P\) — начальный вклад;
- \(r\) — годовая процентная ставка (в десятичной форме);
- \(m\) — количество капитализаций в году;
- \(n\) — количество лет.
Формат входных данных
В первой строке одно целое число — начальная сумма.
Во второй строке одно целое число — процентная ставка.
В третьей строке одно целое число — срок кредита в годах.
Формат выходных данных
Единственное целое число — сумма вклада по окончании срока с учетом капитализации процентов.
Тестовые данные
| Номер теста | Стандартный ввод | Стандартный вывод |
|---|---|---|
1 |
100000 6 2 |
112649 |
Ниже представлено решение на языке Python.
import math
def calculate_final_amount(principal, annual_rate, years, compounding_frequency):
rate_per_period = annual_rate / 100 / compounding_frequency
total_periods = years * compounding_frequency
final_amount = principal * (1 + rate_per_period) ** total_periods
return final_amount
principal = int(input()) # начальная сумма вклада
annual_rate = int(input()) # годовая процентная ставка
years = int(input()) # срок вклада в годах
compounding_frequency = 4 # количество капитализаций в год (ежеквартально)
# Вычисляем итоговую сумму, используем функцию math.floor,
# чтобы получить только целую часть
final_amount = math.floor(calculate_final_amount(principal, annual_rate, years, compounding_frequency))
print(final_amount)
Георгий собирается взять кредит на некую сумму в рублях. Банк предлагает погашать кредит равными ежемесячными платежами (аннуитетные платежи). Напишите функцию для расчета ежемесячного платежа по кредиту. На вход функции должны подаваться следующие данные:
- сумма кредита;
- годовая процентная ставку (в процентах);
- срок кредита в годах.
Не забудьте рассчитать ежемесячный платеж по кредиту по формуле аннуитета: \[A = P \cdot \frac{r \cdot (1 + r)^n}{(1 + r)^n - 1},\] где
- \(A\) — аннуитетный платеж;
- \(P\) — сумма кредита;
- \(r\) — месячная процентная ставка (годовая ставка делится на 12 и переводится в десятичную дробь);
- \(n\) — общее количество платежей (количество месяцев).
Для написания функции используйте язык программирования Python. Для того чтобы ответ был засчитан корректно, функция должна выводить только целую часть числа без округления.
Формат входных данных
В единственной строке три целых числа, разделенных пробелом: сумма кредита, процентная ставка и срок кредита в годах.
Формат выходных данных
Единственное целое число — сумма ежемесячного платежа по кредиту.
Тестовые данные
| Номер теста | Стандартный ввод | Стандартный вывод |
|---|---|---|
1 |
521000 12 3 |
17304 |
Ниже представлено решение на языке Python.
import math
def calculate_monthly_payment(principal, annual_rate, years):
# Преобразуем годовую процентную ставку в месячную
monthly_rate = annual_rate / 100 / 12
total_payments = years * 12
# Рассчитываем ежемесячный платеж по формуле аннуитета
monthly_payment = principal * (monthly_rate * (1 + monthly_rate) ** total_payments) / ((1 + monthly_rate) ** total_payments - 1)
return monthly_payment
principal, annual_rate, years = (int(x) for x in input().split())
# сумма кредита, годовая процентная ставка (в процентах!) и срок кредита в годах
# Вычисляем ежемесячный платеж, используем функцию math.floor,чтобы получить только целую часть
monthly_payment = math.floor(calculate_monthly_payment(principal, annual_rate, years))
print(monthly_payment)
Программист получает зарплату, которая зависит не только от уровня и количества технологий, но и от дополнительных бонусов.
Бонусы начисляются за участие в проектах:
- за каждый проект начисляется \(X\) руб.;
- программист уровня Junior получает базовую ставку 45000 руб. и по 4000 руб. за каждую технологию;
- программист уровня Middle получает базовую ставку 90000 руб. и по 8000 руб. за каждую технологию;
- программист уровня Senior получает базовую ставку 140000 руб. и по 15000 руб. за каждую технологию.
Напишите функцию, которая принимает на вход количество технологий, количество проектов и бонус за каждый проект в рублях (целое, положительное число рублей, строго больше нуля) через пробел и возвращает зарплату программистов всех уровней с учетом всех факторов в одной строке через пробел.
Для написания функции используйте язык программирования Python. Для того чтобы ответ был засчитан корректно, функция должна выводить только целую часть числа без округления.
Формат входных данных
Единственная строка содержит три целых числа, разделенных пробелом: количество технологий, количество проектов и бонус.
Формат выходных данных
В одной строке через пробел три целых числа: зарплата программистов всех уровней в порядке Junior, Middle, Senior.
Тестовые данные
| Номер теста | Стандартный ввод | Стандартный вывод |
|---|---|---|
1 |
2 1 5000 |
58000 111000 175000 |
Ниже представлено решение на языке Python.
def calculate_salary_with_bonus(level, tech_count, project_count, bonus):
if level == 'Junior':
base_salary = 45000
bonus_per_tech = 4000
elif level == 'Middle':
base_salary = 90000
bonus_per_tech = 8000
elif level == 'Senior':
base_salary = 140000
bonus_per_tech = 15000
else:
return 0
project_bonus = project_count * bonus
return base_salary + bonus_per_tech * tech_count + project_bonus
technologies_count, projects_count, bonus = (int(x) for x in input().split())
junior = math.floor(calculate_salary_with_bonus('Junior', technologies_count, projects_count, bonus))
middle = math.floor(calculate_salary_with_bonus('Middle', technologies_count, projects_count, bonus))
senior = math.floor(calculate_salary_with_bonus('Senior', technologies_count, projects_count, bonus))
print(junior, middle, senior)
Допустим, речь идет об инвестициях в акции. Имеются данные о месячной доходности акций за последние 12 месяцев. Чтобы оценить риск инвестиций, нужно рассчитать стандартное отклонение доходности, которое показывает, насколько сильно доходность может колебаться от среднего значения.
Напишите функцию, которая принимает список из 12 значений доходности (в процентах) в качестве строки (чисел, разделенных пробелами) и возвращает стандартное отклонение. Для написания функции используйте язык программирования Python. Для того чтобы ответ был засчитан корректно, функция должна выводить стандартное отклонение в процентах, округленное до двух знаков после запятой, используя функцию round (или ее аналог).
Примечание
Возможно, потребуется импортировать библиотеку math, и если нужно почитать подробнее про стандартное отклонени, рекомендация https://journal.tinkoff.ru/indicators/.
Формат входных данных
В единственной строке список из 12 целых чисел, разделенных пробелами — значений доходности (в процентах).
Формат выходных данных
Единственное число — стандартное отклонение в процентах, округленное до двух знаков после запятой (разделитель — точка).
Тестовые данные
| Номер теста | Стандартный ввод | Стандартный вывод |
|---|---|---|
1 |
5 7 -3 8 6 2 10 -1 4 9 3 7 |
3.79 |
Ниже представлено решение на языке Python.
import math
def calculate_std(deviations):
# Находим среднее значение доходности
avg = sum(deviations) / len(deviations)
# Рассчитываем и возвращаем отклонение каждого значения от среднего
variance = sum((x - avg) ** 2 for x in deviations) / len(deviations)
return round(math.sqrt(variance), 2)
input_list = [int(x) for x in input().split()]
print(calculate_std(input_list))Георгий уже начал анализировать финансовые потоки внутри семьи, но поделиться доходами на широкую аудиторию пока не готов. Поэтому он решил предложить вам вместе с ним покопаться в графе «Расходы».
Для этого Георгий аккуратно внес в таблицу все расходы с датами, суммами и категориями расходов и сохранил в формате csv: https://disk.yandex.ru/d/KrD3mMJ1_6ds3Q.
С этим форматом, как настоящим аналитикам, придется работать, используя соответствующую библиотеку pandas. Начало работы с этой библиотекой осуществляется ее импортом в файл проекта с помощью команды import pandas. Для более краткого обращения к библиотеке из кода проекта указывается короткое имя pd:
import pandas as pdPandas — это Python-библиотека, созданная специально для отображения, анализа и обработки структурированных данных. Название библиотеки расшифровывается как panel data или «панельные данные». Панельными называют данные, представленные в виде таблиц и имеющие четкую структуру (структурированные).
У библиотеки есть официальный сайт, на котором описано, как можно начать работу с этой библиотекой — почитать тут: https://pandas.pydata.org/getting_started.html.
Датафреймы (тип данных DataFrame из библиотеки Pandas) — это таблица со строками и столбцами, которая похожа на таблицу из приложения Excel. В этом типе данных можно разместить данные из нашего csv-файла и потом их обрабатывать: сортировать, группировать, производить вычисления.
df, используя функцию: pd.read_csv('expenses.csv', index_col=[0], parse_dates=[0])В функции pd.read_csv() из библиотеки Pandas параметры index_col и parse_dates выполняют следующие функции.
index_col=[0]: данный параметр указывает, что первый столбец (индекс 0) в загружаемомcsv-файле должен использоваться в качестве индекса для датафрейма. Это значит, что значения из этого столбца будут служить уникальными метками для строк, а не просто обычным столбцом данных.parse_dates=[0]: данный параметр указывает, что первый столбец (также индекс 0) нужно интерпретировать как даты. То есть, если в этом столбце находятся даты, Pandas автоматически преобразует их в форматdatetime, что позволяет удобно работать с временными рядами и выполнять операции с датами.
Таким образом, эта строка кода загружает данные из файла expenses.csv, устанавливает первый столбец в качестве индекса и преобразует его в формат даты.
data = pd.read_csv('НАЗВАНИЕ_ФАЙЛА.csv', index_col=[0], parse_dates=[0])Выведем первые 10 строк датафрейма и информацию о полях датафрейма. Столбцы называются полями.
Проверим, что все считано корректно.
data.head(10)
data.info()Задание 1. Типы данных (2 балла)
Выведите тип данных для колонки category (полное название типа данных с маленькой буквы).
Задание 2. Типы данных (2 балла)
Выведите тип данных для колонки amount (полное название типа данных с маленькой буквы).
Для подготовки данных нужно проверить несколько моментов:
- проверить данные на количество пропусков;
- проверить данные на наличие дубликатов (явных или неявных).
Задание 3. Поиск пропусков (3 балла)
Выведите общее количество пропусков во всех столбцах данных.
Заполним пропуски в разделеcategory значением «Прочее»: data['category'] = data['category'].fillna('Прочее')Задание 4. Поиск неявных дубликатов (3 балла)
Заполните пропущенные значения категории Amount средним значением по каждой категории трат.
Было.
| name | value | |
|---|---|---|
| 0 | A | 2 |
| 1 | A | NaN |
| 2 | B | NaN |
| 3 | B | 4 |
| 4 | B | 3 |
| 5 | B | 1 |
| 6 | C | 3 |
| 7 | C | NaN |
| 8 | C | 1 |
Стало.
| name | value | |
|---|---|---|
| 0 | A | 2 |
| 1 | A | 2 |
| 2 | B | 4 |
| 3 | B | 4 |
| 4 | B | 3 |
| 5 | B | 1 |
| 6 | C | 3 |
| 7 | C | 3 |
| 8 | C | 1 |
Выведите среднее значение среди всех платежей независимо от категории после удаления пропусков по всему столбцу платежей. В ответе укажите только целую часть числа без округления.
Неявный дубликат в датафрейме — это строки, которые выглядят почти одинаково, но не совсем идентичны. Например, представьте, что есть таблица с именами, и в ней есть «Георгий» и «георгий». На первый взгляд, они похожи, но из-за разного регистра букв (большие и маленькие) это уже не совсем одно и то же. Такие дубликаты могут мешать анализу данных, потому что можно не заметить, что это одно и то же имя. Важно следить за такими нюансами, чтобы не запутаться! Опечатки тоже могут быть неявными дубликатами, смысловые синонимы тоже (например, «Развлечение» и «На развлечения»).
Посмотрим все уникальные значения в графе категории, чтобы отловить неявные дубликаты. И уберем их для того, чтобы продолжить дальше работу. Подобные ситуации часто встречаются при работе с данными, именно так можно научиться с ними работать.
С помощьюdata['category'].unique() проверим, что названия категорий не содержат грамматических ошибок и не повторяются. data['category'] = data['category'].replace('Прочее', 'Прочие расходы')
data['category'] = data['category'].replace('Комунальные услуги', 'Коммунальные услуги')
data['category'] = data['category'].replace('Продукт', 'Продукты')
data['category'] = data['category'].replace('Абразование', 'Образование')
data['category'] = data['category'].replace('Транспарт', 'Транспорт')
data['category'] = data['category'].replace('Прадукты', 'Продукты')
data['category'] = data['category'].replace('образование', 'Образование')
data['category'].unique()data['year'] = data.index.year
data['month'] = data.index.month
data['day'] = data.index.day
data['dayofweek'] = data.index.dayofweek
data.head()Задание 5. День недели (10 баллов)
Выведите номер дня недели, в который совершали больше всего трат. Напишите программу, которая считает количество вхождений каждого номера дня недели, и выбирает тот, что встречается чаще всего. В ответ выведите номер (десятичную цифру). Если таких значений несколько — выведите наибольшую цифру.
Теперь можно перейти к анализу.
Задание 6. Основы статистики (10 баллов)
Есть данные о ежемесячных расходах семьи Георгия за два года. Задача — найти средний месячный расход в каждой категории: продукты питания, коммунальные услуги, транспорт, развлечения и другие расходы. В ответе выведите число: разность минимального и максимального среднемесячного расхода среди категорий (самой затратной и самой «легкой» категории). Если числа получаются дробными, то выведите только целую часть.
Задание 7. Основы статистики 2 (10 баллов)
Есть данные о ежемесячных расходах семьи Георгия. Задача — найти средний месячный расход в каждой категории в январе: продукты питания, коммунальные услуги, транспорт, развлечения и прочие расходы.
Предположим, что месяц был не из веселых, Георгий только дважды ходил в кино — один раз за 400 руб. и второй раз — за 600 руб., и больше никаких развлечений не было. Средний месячный расход в категории Развлечения — 500 руб. (\((600 + 400)/2\)).
Зная такое значение в каждой категории, можно эти категории сравнить и выбрать ту, где расход был максимальным. А также определить, как для этой категории расходов рядовые траты отклоняются от среднего значения с помощью функции std(). В ответе выведите максимальное среднемесячное значение расходов среди всех категорий за январь. Если число получается дробным, то выведите только целую часть.
Задание 8. Основы статистики 3 (10 баллов)
Выведите значение среднеквадратичного отклонения для категории с максимальными среднемесячными расходами. Если число получается дробным, то выведите только целую часть.
Задание 9. Основы статистики 4 (10 баллов)
Георгий заметил, что расходы на продукты в разные месяцы имеют сезонный характер. Он решил запланировать свой бюджет на следующий год, основываясь на данных о расходах за прошлый год. Георгий хочет увеличить свои расходы на Образование (сумму трат) в каждом месяце на 10% в следующем году.
Задача: какой будет общий бюджет Георгия на образование в следующем году с учетом увеличения расходов на 10%? Напишите функцию для расчета общего бюджета на образование. В ответе укажите итоговую сумму в рублях. Если числа получаются дробными, то выведите только целую часть.
Задание 10. Сравнение средних квартальных расходов (10 баллов)
Георгий решил проанализировать свои расходы на продукты за год, чтобы понять, в каком квартале семья тратит больше всего, и сделать соответствующие выводы!
Найдите средние расходы Георгия на продукты за год и определите, на сколько рублей расходы в первом квартале превышают средние расходы по году.
Напишите функцию для расчета общего бюджета на продукты. В ответе укажите итоговую сумму в рублях. Если числа получаются дробными, то выведите только целую часть — округлите вниз.
- 1 квартал: январь, февраль и март.
- 2 квартал: апрель, май и июнь.
- 3 квартал: июль, август и сентябрь.
- 4 квартал: октябрь, ноябрь и декабрь.
Задание 11. Определение тенденции расходов и планирование экономии (10 баллов)
Георгий хочет проанализировать свои ежемесячные расходы за последний год в категории Развлечения, чтобы выявить тенденцию и определить, сколько он может сэкономить в следующем месяце. Он планирует веселиться чуть бюджетнее и установить цель по экономии — уменьшить свои расходы на 15% от среднего значения. Задача:
- Вычислите средние ежемесячные расходы за год по категории Развлечения (расходы за каждый месяц).
- Определите, сколько Георгий может сэкономить, установив цель по экономии в 15% от рассчитанного среднего значения (Георгий сокращает расходы в каждом месяце).
- Выведите сумму, которую Георгий сможет сэкономить, если будет реже ходить в кино и сам варить шарики для бабл-чая.
Задание 12. Крупная трата — сумма (10 баллов)
Однажды Георгий задумался, почему в конце января родители урезают его карманные расходы, которые он копит, чтобы купить Tesla. Куда вообще уходят деньги семьи в январе?! Ведь Георгий не ездит в школу, завтракает дома и целыми днями играет в видеоигры. Да и родители отдыхают дома и не тратятся на дорогу и обеды в столовой. Георгий что-то слышал про то, что за выходные не платят, но не может же все быть так просто. Наверное, родители тайно покупают себе что-то вкусное, а потом страдает семейный бюджет и финансовые цели Георгия.
Напишите программу, которая определяет, какая была наибольшая трата за январь. В ответе укажите итоговую сумму в рублях. Если числа получаются дробными, то в ответы впишите только целую часть.
Задание 13. Крупная трата — категория (10 баллов)
Выведите категорию самой крупной траты из предыдущего задания. Категорию необходимо написать ровно так, как она отображается.
Пример решения
Ниже приведен шаблон (пример) кода, который необходимо загрузить в качестве решения. Пример является корректным с точки зрения формата (так как содержит ровно 13 команд вывода ответов), но оценивается в 0 баллов. Ваша задача — написать код аналогичный по структуре, но выводящий правильные ответы на задания.
import pandas as pd
data = pd.read_csv('expenses.csv', index_col=[0], parse_dates=[0])
# TODO Напишите тут свой код, вычисляющий правильные ответы
# и выведите эти ответы в том же порядке, в котором они указаны в условии задачи
print("unknown") #todo Заменить своим кодом, это неправильный ответ на 1 вопрос
print("unknown") #todo Заменить своим кодом, это неправильный ответ на 2 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 3 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 4 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 5 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 6 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 7 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 8 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 9 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 10 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 11 вопрос
print(0) #todo Заменить своим кодом, это неправильный ответ на 12 вопрос
print("unknown") #todo Заменить своим кодом, это неправильный ответ на 13 вопросНиже представлено решение на языке Python.
import pandas as pd
data = pd.read_csv('expenses_var_1.csv', index_col=[0], parse_dates=[0])
task1 = str(data['category'].dtype)
task2 = str(data['amount'].dtype)
task3 = data.isna().sum().sum()
data['category'] = data['category'].fillna('Прочее')
data['amount'] = data['amount'].fillna(data.groupby( 'category')['amount'].transform('mean' ))
task4 = math.floor(data['amount'].mean())
data['category'] = data['category'].replace('Прочее', 'Прочие расходы')
data['category'] = data['category'].replace('Комунальные услуги', 'Коммунальные услуги')
data['category'] = data['category'].replace('Продукт', 'Продукты')
data['category'] = data['category'].replace('Абразование', 'Образование')
data['category'] = data['category'].replace('Транспарт', 'Транспорт')
data['category'] = data['category'].replace('Прадукты', 'Продукты')
data['category'] = data['category'].replace('образование', 'Образование')
#data['category'].unique()
data['year'] = data.index.year
data['month'] = data.index.month
data['day'] = data.index.day
data['dayofweek'] = data.index.dayofweek
#data.head()
task5 = data['dayofweek'].mode().max()
task6 = math.floor(data.groupby('category')['amount'].mean().max() - data.groupby('category')['amount'].mean().min())
task7 = math.floor(data.loc[data['month'] == 1].groupby('category')['amount'].mean().max())
task8 = math.floor(data.loc[(data['month'] == 1) & (data['category'] == 'Продукты')]['amount'].std())
budget = 0
data_cat_month = data.loc[data['category'] == 'Образование'].groupby('month').sum()
for i in data_cat_month['amount']:
budget += i*1.1
task9 = math.floor(budget)
def kvartal(df):
if df['month'] in [1, 2, 3]:
return 1
if df['month'] in [4, 5, 6]:
return 2
if df['month'] in [7, 8, 9]:
return 3
return 4
data['kvartal'] = data.apply(kvartal, axis = 1)
data_products = data.loc[data['category'] == 'Продукты']
mean_kvartal = data_products.loc[data_products['kvartal'] == 2]['amount'].mean()
full_mean = data_products['amount'].mean()
task10 = math.floor(mean_kvartal - full_mean)
task11 = math.floor((data.loc[data['category'] == 'Развлечения'].groupby('month').mean()['amount']*0.15).sum())
max_amount_yan = data.loc[data['month'] == 1]['amount'].max()
task12 = math.floor(data.loc[(data['month'] == 1) & (data['amount'] == max_amount_yan)]['amount'])
cat = data.loc[(data['month'] == 1) & (data['amount'] == max_amount_yan)]['category']
task13 = str(cat).split()[3]
# TODO Напишите тут свой код, вычисляющий правильные ответы
# и выведите эти ответы в том же порядке, в котором они указаны в условии задачи
print(task1)
print(task2)
print(task3)
print(task4)
print(task5)
print(task6)
print(task7)
print(task8)
print(task9)
print(task10)
print(task11)
print(task12)
print(task13)
Для набора данных 1: https://disk.yandex.ru/d/KrD3mMJ1_6ds3Q/expenses_var_1.csv
object
float64
30
10198
4
1359
11060
2890
1856189
436
19665
19689
ОбразованиеДля набора данных 2: https://disk.yandex.ru/d/KrD3mMJ1_6ds3Q/expenses_var_2.csv
object
float64
31
9799
4
530
13313
4317
1727901
665
17521
19890
ПродуктыДля набора данных 3: https://disk.yandex.ru/d/KrD3mMJ1_6ds3Q/expenses_var_3.csv
object
float64
26
10380
5
1283
10422
5896
2074305
194
19555
18666
РазвлеченияРешение задачи должно считать данные из CSV-файла и вывести в консоль ответы на 13 заданий, представленных выше. Каждый ответ должен быть выведен на отдельной строке (например, функцией print()).
Задача будет проверяться на трех разных файлах с данными, каждый из которых будет доступен вашему решению в файле expenses.csv.
Таким образом, решение при проверке будет запущено три раза, каждый раз на входе будет доступен новый (по содержимому) файл с одним и тем же именем expenses.csv. После чтения и обработки файла решение должно вывести 13 строк с ответами и завершиться.
За каждый такой тест на отдельном файле данных можно получить до 100 баллов.
Итоговый балл является суммой баллов за три теста — то есть максимально за задачу можно получить 300 баллов.
Для того кто планирует быть топовым программистом, очень важно отличное образование. Георгий это понимает. Для оптимального распределения финансов в его жизни выгоднее поступить на бюджет. Но случиться может всякое. И Георгий решил посчитать, во что ему могут обойтись последствия залипания в интернете — образовательный кредит, чтобы оплатить обучение в университете на контракте. Он хочет понять, как будет изменяться его задолженность по кредиту в зависимости от ежемесячных платежей и процентной ставки. Кредит выплачивается равными аннуитетными платежами (изучите, что это, и найдите формулу расчета).
На вход функции должны подаваться следующие данные в одну строку через пробел:
- сумма кредита;
- годовая процентная ставку (в процентах);
- срок кредита в годах (не менее двух лет).
Напишите программу на Python, которая рассчитывает:
- общую сумму, которую Георгий должен будет вернуть по кредиту с учетом процентов;
- общую сумму процентов, которые он заплатит за весь срок кредита;
- остаток долга на конец каждого месяца.
В качестве ответа выведите через пробел общую сумму, общую сумму процентов и остаток долга на 14-й месяц выплаты. Для написания функции необходимо использовать язык программирования Python. Для того чтобы ответ был засчитан корректно, функция должна выводить только целую часть числа без округления (!).
Формат входных данных
В единственной строке три целых числа через пробел — сумма кредита, годовая процентная ставка (в процентах), срок кредита в годах (не менее двух лет).
Формат выходных данных
В единственной строке три целых числа через пробел — общая сумма, общая сумма процентов и остаток долга на 14-й месяц выплаты.
Тестовые данные
| Номер теста | Стандартный ввод | Стандартный вывод |
|---|---|---|
1 |
550000 12 3 |
657643 107643 359153 |
Ниже представлено решение на языке Python.
import math
# Функция для расчета аннуитетного платежа
def calculate_annuity_payment(S, r, n):
r_month = r/ 100 / 12 # Месячная процентная ставка
A = S * (r_month * (1 + r_month) ** n) / ((1 + r_month) ** n - 1)
return A
# Функция для расчета остатка долга на конец k-го месяца
def calculate_remaining_debt(A, r, n, k):
r_month = r / 100/ 12 # Месячная процентная ставка
B_k = A * ((1 + r_month) ** n - (1 + r_month) ** k) / r_month
return B_k
# Входные данные
S, r, n = (int(x) for x in input().split()) # Сумма кредита
n =n*12
A = calculate_annuity_payment(S, r, n)
total_payment = math.floor(A * n)
total_interest = math.floor(total_payment - S)
# Остаток долга на конец 14-го месяца
debt_after_14_months = math.floor(calculate_remaining_debt(A, r, n, 14))
print(total_payment, total_interest, debt_after_14_months)
Георгий подумал, что для бо́льшего контроля хорошо бы сохранить сведения о тратах в базу данных. И решил разобраться, как это сделать. Он собирается создать таблицу в базе данных с помощью Python, чтобы хранить информацию о расходах семьи. Он начал с изучения основ работы с базами данных и библиотек, которые могут помочь ему в этом процессе.
SQL (Structured Query Language) — это язык программирования, который используется для управления и манипуляции данными в реляционных базах данных. Одной из основных операций в SQL является создание таблиц, которые служат для хранения данных в структурированном виде.
- Команда
CREATE TABLE: используется для создания новой таблицы в базе данных. - Имя таблицы: указывается сразу после команды
CREATE TABLEи должно быть уникальным в пределах базы данных. - Поля таблицы: каждое поле (или столбец) описывается с указанием имени и типа данных. Тип данных определяет, какой вид информации может храниться в этом поле (например, целые числа, дробные числа, текст и т. д.).
- Первичный ключ (
PRIMARY KEY): это поле или набор полей, которые уникально идентифицируют каждую запись в таблице. Обычно используется для обеспечения уникальности записей. - Автоинкремент (
AUTOINCREMENT): специальный атрибут для целочисленных полей, который позволяет автоматически увеличивать значение при добавлении новых записей.
- https://www.w3schools.com/sql/sql_create_table.asp. Этот ресурс предлагает простое и понятное объяснение команды
CREATE TABLE, а также примеры использования. - https://www.tutorialspoint.com/sql/sql-create-table.htm. Здесь можно найти более детальную информацию о создании таблиц, включая синтаксис и различные типы данных, используемые в SQL.
Эти ресурсы помогут Георгию и его друзьям лучше понять основы создания таблиц в SQL и начать работу с базами данных.
Георгий выбрал SQLite как систему управления базами данных, поскольку она проста в использовании и не требует установки отдельного сервера. SQLite идеально подходит для небольших проектов и позволяет хранить данные в одном файле.
Для работы с SQLite в Python Георгий использовал встроенный модуль sqlite3, который позволяет взаимодействовать с базой данных. Ему не нужно было устанавливать дополнительные библиотеки, так как sqlite3 уже включен в стандартную библиотеку Python.
sqlite3 в свой скрипт: import sqlite3
from sqlite3 import connectsqlite3 автоматически создал бы новый файл базы данных: conn = sqlite3.connect('transactions.db')cursor = conn.cursor()id, loan_amount, loan_term, monthly_payment, и remaining_balance. Он использовал SQL-запрос для создания таблицы: cursor.execute('''
CREATE TABLE IF NOT EXISTS loans (
id INTEGER PRIMARY KEY AUTOINCREMENT,
loan_amount REAL,
loan_term INTEGER,
monthly_payment REAL,
remaining_balance REAL
)
''')В таблице loans Георгий определил несколько полей, каждое из которых имеет свое назначение и тип данных. Вот описание каждого поля и обоснование выбора типов данных:
id INTEGER PRIMARY KEY AUTOINCREMENT- Описание: это уникальный идентификатор для каждой записи в таблице. Он автоматически увеличивается при добавлении новой записи.
- Тип данных:
INTEGER. Обоснование: использование целочисленного типа данных для идентификатора позволяет легко отслеживать и ссылаться на записи.
AUTOINCREMENTгарантирует, что каждый новый идентификатор будет уникальным и не повторится.
loan_amount REAL- Описание: это сумма кредита, которую Георгий взял.
- Тип данных:
REAL. - Обоснование:
REALиспользуется для хранения чисел с плавающей запятой, что позволяет точно представлять суммы, включая дробные значения. Это важно для финансовых данных, так как суммы кредитов могут быть нецелыми.
loan_term INTEGER- Описание: это срок кредита в месяцах.
- Тип данных:
INTEGER. - Обоснование: срок кредита выражается в целых числах (например, 12 месяцев, 24 месяца и т. д.), поэтому для этого поля используется целочисленный тип данных.
monthly_payment REAL- Описание: это сумма ежемесячного платежа по кредиту.
- Тип данных:
REAL. - Обоснование: как и для суммы кредита,
REALпозволяет хранить значения с плавающей запятой, что важно для точного представления ежемесячных платежей, которые могут включать дробные значения.
remaining_balance REAL- Описание: это остаток по кредиту, который еще нужно выплатить.
- Тип данных:
REAL. - Обоснование: остаток по кредиту также может быть дробным числом, поэтому для этого поля выбран тип
REAL, что позволяет точно отслеживать оставшуюся сумму долга.
cursor.execute('''
INSERT INTO loans (loan_amount, loan_term, monthly_payment, remaining_balance)
VALUES
(500000, 36, 15000, 450000),
(300000, 24, 12000, 200000),
(1000000, 60, 25000, 950000),
(200000, 12, 17000, 150000),
(400000, 24, 18000, 350000),
(750000, 48, 22000, 700000),
(550000, 36, 16000, 500000),
(900000, 48, 23000, 850000),
(1200000, 60, 27000, 1150000),
(600000, 36, 19000, 550000);
''')
query = '''
SELECT * FROM loans
'''
df_sql = pd.read_sql(query, conn)
df_sqlconn.commit()
conn.close()Георгий успешно создал таблицу в базе данных, что позволило ему хранить и управлять данными о своем образовательном кредите. Он понял, что использование баз данных значительно упрощает процесс работы с данными и позволяет легко их организовывать и извлекать. Теперь он мог добавлять, изменять и запрашивать информацию о своих финансах, что помогло ему лучше планировать свои расходы. И потом использовать, если ему захочется разработать приложение, которое будет пользоваться этой базой.
Георгию необходимо создать таблицу для учета своих исходных расходов и доходов. Таблица должна содержать следующие поля.
- Дата (date): дата транзакции.
- Сумма (amount): сумма транзакции.
- Категория (category): категория траты.
expenses_db.csv. conn = sqlite3.connect('expenses.db')
cursor = conn.cursor()
data_to_sql = pd.read_csv('expenses_db.csv')
data_to_sql.to_sql('expenses', conn, if_exists='replace', index=False)query = '''
SELECT * FROM expenses LIMIT 10;
'''
df_sql = pd.read_sql(query, conn)
df_sqlSELECT * FROM название_таблицыcursor.execute('SELECT count(*) FROM expenses')
result = cursor.fetchone()
print(result[0])Результат запроса: 1000.
- Запросы написаны верно, дан верный ответ — 100.
- Запросы написаны верно, неверный формат вывода ответа (при этом ответ верный) — 75.
- Запросы написаны верно, нет вывода ответа — 50.
- Запросы написаны неверно, не написаны, код не запускается, представлен только ответ, ответ неверный — 0.
Напишите SQL-запрос, который посчитает, сколько было платежей (независимо от категории) выше 2000 руб. по вторникам.
cursor.execute(
'''SELECT count(*) FROM expenses
WHERE amount > 2000 AND dayofweek = 1'''
)
result = cursor.fetchone()
print(result[0])145.
Примечание
Обратите внимание на нумерацию дней недели в базе данных.
- Запросы написаны верно, дан верный ответ — 100.
- Запросы написаны верно, неверный формат вывода ответа (при этом ответ верный) — 75.
- Запросы написаны верно, нет вывода ответа — 50.
- Запросы написаны неверно, не написаны, код не запускается, представлен только ответ, ответ неверный — 0.
Выведите количество записей о расходах из категорий «Коммунальные услуги», «Продукты», «Транспорт».
cursor.execute(
'''SELECT count(*) FROM expenses
WHERE category IN ('Коммунальные услуги',
'Продукты',
'Транспорт');'''
)
result = cursor.fetchone()
print(result[0])- Запросы написаны верно, дан верный ответ — 100.
- Запросы написаны верно, неверный формат вывода ответа (при этом ответ верный) — 75.
- Запросы написаны верно, нет вывода ответа — 50.
- Запросы написаны неверно, не написаны, код не запускается, представлен только ответ, ответ неверный — 0.
В этой задаче Георгию потребуются библиотеки ipywidgets и IPython. display.
import ipywidgets as widgets
from IPython.display import display, clear_outputИспользуя библиотеку ipywidgets, нарисуйте интерфейс, который показан на рис. 2.1. Интерфейс должен выводить запись под установленные параметры пользователя.
Необходима опция выбора даты и категории расхода. Вывод данных осуществляется по нажатию кнопки Вывести расходы.
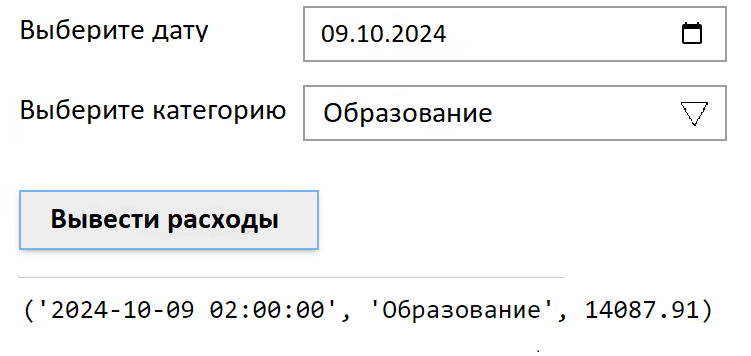
Вывод данных является лишь примером вывода.
Ниже представлено решение на языке Python.
import sqlite3
import pandas as pd
import ipywidgets as widgets
from IPython.display import display
conn = sqlite3.connect('expenses.db')
cursor = conn.cursor()
data_to_sql = pd.read_csv('expenses_db.csv')
data_to_sql.to_sql('expenses', conn, if_exists='replace', index=False)
query = "SELECT DISTINCT category FROM expenses;"
response = pd.read_sql(query, conn)
categories = response['category']
date_w = widgets.DatePicker(
description='Выберите дату: ',
disabled=False,
)
cat_w = widgets.Dropdown(
options=categories ,
value=categories [0],
description='Выберите категорию:',
disabled=False,
)
button = widgets.Button(
description='Вывести расходы',
disabled=False,
tooltip='Вывести расходы',
)
output = widgets.Output(layout={'border': '1px solid black'})
display(date_w, cat_w, button, output)
def on_button_clicked(b):
output.clear_output()
if date_w.value:
query = f'''
SELECT date, amount, category
FROM expenses
WHERE category = '{cat_w.value}'
AND year={date_w.value.year}
AND month={date_w.value.month}
AND day={date_w.value.day};
'''
result = pd.read_sql(query, conn)
with output:
for index, row in result.iterrows():
print(row['date'], row['category'], row['amount'])
else:
with output:
print("Не указана дата")
button.on_click(on_button_clicked)
Вариант отображения и вывода.
Дата: 14 октября 2024 годаВывод:
2024-10-14 08:55:17 Развлечения 14802.74
2024-10-14 20:04:38 Развлечения 12882.39
2024-10-14 07:21:21 Развлечения 877.85
2024-10-14 01:52:05 Развлечения 14077.49Отображение интерфейса на рис. 2.2.
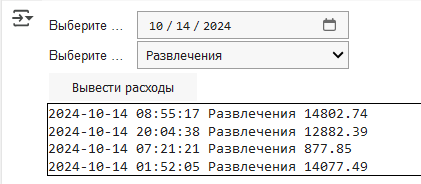
Оценка формируется путем суммирования двух баллов — за отрисовку интерфейса (виджета) и за взаимодействие интерфейса с данными.
Балл за отрисовку интерфейса — от 0 до 25.
- Виджет отрисован и отображается корректно по заданию — 25.
- Виджет отрисован схоже, но есть неточности (например, выбор категории — не выпадающий список) — 10.
- Виджет отрисован некорректно, требует перезагрузки кода для повторного нажатия и/или не реагирует на нажатия — 0.
Балл за взаимодействие интерфейса с данными — от 0 до 75.
- Данные отображаются корректно и в полном объеме — 75.
- Данные отображаются под запрос, но не все записи (вывод частичный), сформирован неполный список категорий — 50.
- Допущены неточности и ошибки в интерфейсе, которые могут повлиять на корректность вывода данных (например, неполный список категорий). В остальном код написан и отрабатывает корректно — 25.
- Данные отображаются некорректно — 0.





