
Инженерный тур. 2 этап
Задача имеет целью выявить навыки работы участников с алгоритмами классификации для разработки модели, способной автоматически классифицировать группу животных на фото с фотоловушек. В процессе выполнения заданий проверяются компетенции участников в обработке данных и применении алгоритмов машинного обучения, а также способность погружаться в предметную сферу и использовать алгоритмы компьютерного зрения в решении задач.
Задача помогает оценить участников по их знаниям и навыкам в области программирования, зоологии, обработки изображений, машинного обучения и применении технических решений для решения реальных проблем.
Задача посвящена многоклассовой детекции животных.
Для этого участники получат доступ к уникальным данным — изображениям с фотоловушек, предоставленным исследовательскими организациями-партнерами. Решение задачи позволит отфильтровать пустые изображения, изображения с людьми, транспортом и выделить изображения с животными по группам.
Все материалы и данные к задаче доступны по ссылке: https://disk.yandex.ru/d/hbZfV-2Dq9qJVQ.
Мониторинг популяции диких животных — важная задача для мирового сообщества исследователей дикой природы. Ее решение помогает узнать, какие виды животных находятся под угрозой исчезновения, как они себя ведут в разные периоды жизни, где обитают и многое другое.
Для мониторинга животных используют различные инструменты, в том числе и фотоловушки — специальные камеры, устанавливаемые в лесу и реагирующие на движение в кадре. Каждый год с этих камер приходят сотни тысяч фотографий, на которых нужно найти и категоризировать животных. Это очень сложная и кропотливая работа, так как общее число видов может достигать нескольких сотен, могут встречаться и такие, которые визуально друг от друга трудно различимы. К тому же в кадр в момент активации камеры может попасть лишь часть животного, и из-за того, что активность многих видов приходится на ночное время суток, некоторые фотографии могут быть смазанными или засвеченными из специфики работы камер в ночное время.
В рамках Олимпиады НТО участникам предлагается помочь ученым автоматизировать рутинную работу по обработке данных с фотоловушек, обучив для этого модели машинного обучения.
Для первичной фильтрации сырых данных и дальнейшей обработки (аналитики и изучения каждой отдельной особи) потребуется разработать многоклассовый детектор фотографий животных на отдельные группы, организованные по принципу схожести видов, имеющихся в данных (например, сибирская косуля, пятнистый олень, изюбрь и марал отнесены к оленевым).
Для оценки качества работы модели многоклассовой детекции используется метрика mAP 0,5–0,95 — подсчет средней точности (AP — Average Precision) для каждого класса при различных значениях порога IoU (Intersection over Union) от 0,5 до 0,95 с шагом 0,05 (минимальное IoU для рассмотрения положительного совпадения) с дальнейшим усреднением по классам.
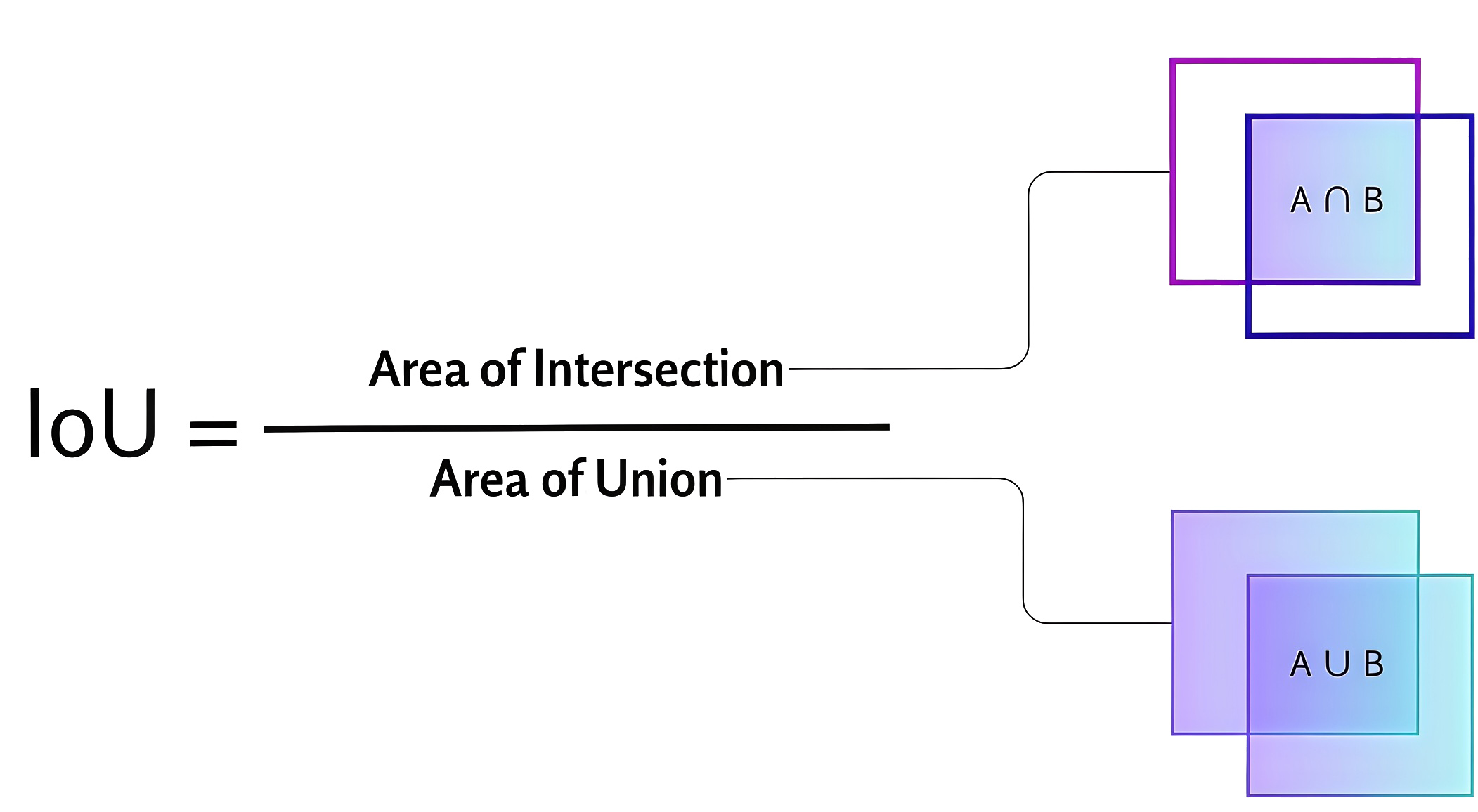
Для каждого класса \(c\) вычисляется среднее значение AP по всем порогам IoU: \[\text{mAP}_{c} = \frac{1}{N} \sum_{i=1}^{N} \text{AP}_{c, \tau_i},\] где \(N = 10\) — количество значений порога IoU (от 0,5 до 0,95 с шагом 0,05).
Среднее значение AP по всем классам (mAP) рассчитывается как: \[\text{mAP} = \frac{1}{C} \sum_{j=1}^{C} \text{mAP}_{j},\] где \(C\) — общее количество классов.
Значение метрики варьируется от 0 (в худшем случае) до 1, если все ограничивающие прямоугольники точно совпадают с истинными и правильно предсказаны классы для них.
Подсчет метрики производится автоматически на платформе при отправке решения.
Данные доступны по ссылке: https://disk.yandex.ru/d/hbZfV-2Dq9qJVQ.
Датасет представляет собой набор изображений и файл train.csv с соответствием каждого изображения определенной группе животных и координатами ограничивающих прямоугольников для каждого животного на изображении.
Координатами ограничивающих прямоугольников является центр ограничивающего прямоугольника и его размеры (ширина и высота) в нормализованном виде в промежутке от 0 до 1. Ширина и высота изменяется в диапазоне от 0 до 1.

Ниже представлена связь между индексом группы и ее наименованием:
- — заяц,
- — кабан,
- — кошки,
- — куньи,
- — медведь,
- — оленевые,
- — пантеры,
- — полорогие,
- — собачие,
- — сурок.
Обратите внимание, что в датасете присутствуют сложные примеры: фото, когда в кадр попала небольшая часть животного, много животных перекрывающих друг друга, а также ночные и смазанные снимки.
Данные были размечены специалистами по разметке данных совместно с учеными зоологами.
Данные разделены на тренировочную и тестовую выборки в соотношении примерно 70% / 30%.
Тестовая часть разбита на публичную и приватную в соотношении примерно 40% / 60%.
baseline_detection.ipynb — jupyter-notebook, позволяющий пройти путь от установки библиотек и обучения модели до получения файла с предсказаниями и посмотреть визуально результаты работы алгоритма.
Формат входных данных
Решения принимаются в виде zip-архива размером не более 5 Gb, имеющего структуру:
metadata.json;entry_point— python-файл;- файл с весами модели;
- любые дополнительные файлы, необходимые для работы решения (python-файлы, директории, модели и их веса);
submission.zip— zip-архив, содержащий пример решения для загрузки на платформу и получения метрики.
Текущей директорией для запуска решения и под загрузки весов модели будет являться корень архива.
metadata.json имеет следующий вид:
{
"image": "odsai/nto24-baseline:1.0",
"entry_point": "python -u run.py"
}image— поле с названием docker-образа на https://hub.docker.com/, в котором будет запускаться решение и содержать все необходимые библиотеки;entry_point— команда, при помощи которой запускается файл с предсказанием run.py.
Этот файл должен иметь обязательные параметры:
--img_dir— путь до папки с тестовыми изображениями на платформе;--output_path— путь, по которому проверочная система ожидает результат решения.
Алгоритм для получения предсказания от модели должен сформировать файл с предсказанием, на основании которого происходит расчет метрики. Сам файл представляет собой csv-документ с двумя колонками image_name и predicted_ detection. Строки — это пары с названием файла изображения и соответствующего ему список предсказаний.
Список предсказаний модели имеет следующий формат: \[\begin{aligned} &label_1\text{ }cx_1\text{ }cy_1\text{ }w_1\text{ }h_1\text{ }confidence_1;label_2\text{ }cx_2\text{ }cy_2\text{ }w_2\text{ }h_2\text{ }confidence_2;~...~;\\ &label_n\text{ }cx_n\text{ }cy_n\text{ }w_n\text{ }h_n\text{ }confidence_n, \end{aligned}\] где
- \(label_i\) — идентификатор группы, к которому относится животное;
- \((cx_i, cy_i)\) — координата центра \(i\)-го прямоугольника (в относительных значениях);
- \(w_i, h_i\) — ширина и высота \(i\)-го прямоугольника (в относительных значениях);
- \(confidence_i\) — уверенность модели детекции в предсказании от 0 до 1.
В случае отсутствия предсказанного ограничивающего прямоугольника сформировать предсказание в виде пустой строки ("").
Пример формирования корректного файла с предсказаниями.
Структура файла с предсказаниями, см. таблицу 1.1.
image_name |
predicted_detection |
|---|---|
| cc27b9b56583a615fb3.JPG | 0 0.5 0.5 0.25 0.25 0.9 |
| 087872711fe672676fd.JPG | 0 0.5 0.5 0.5 0.5 0.9;0 0.5 0.5 0.5 0.5 0.9 |
| 424aa1aa8eb5bbdd07.JPG | - |
| c5537eaa60525efd7b.JPG | 0 0.5 0.5 0.25 0.25 0.9 |
| e9f15b67ca49453e28.JPG | 0 0.5 0.5 0.25 0.25 0.9 |
Онлайн-курс по работе с docker: https://ai-academy.ru/training/courses/docker-git/.
В течение одного дня участник может загрузить для оценки не более пяти решений. Учитываются только валидные попытки, получившие численную оценку.
Контейнер с решением запускается в следующих условиях:
- 96 GB оперативной памяти;
- Nvidia v100 32 GB;
- время на выполнение решения: 10 мин на public, 10 мин на private;
- решение не имеет доступа к ресурсам интернета;
- максимальный размер упакованного архива с решением: 5 GB.
Допускается использование открытых (доступных в сети) датасетов с лицензией, позволяющей свободное некоммерческое использование.
Требуется разработать алгоритм для детекции групп животных по фото с фотоловушек и представить его результат работы в виде csv-файла с колонками image_name, predicted_detection.
Решением задачи является csv-файл с предсказанием, пример файла: sample_submission.zip.
Разбор эталонного решения доступен по ссылке: https://gist.github.com/ntomaterials/0e543eb9c086ce419211d5c57ecbe272.
Задача посвящена классификации животных.
Для этого участники получают доступ к уникальным данным — изображениям с фотоловушек, предоставленным исследовательскими организациями-партнерами. Решение задачи должно распределять все изображения с животными на заданные виды животных и организовать оперативный мониторинг раненных животных, контроль выхода диких животных в населенный пункт.
Все материалы к задаче доступны по ссылке: https://disk.yandex.ru/d/Jx8fZJTSsk_LeQ.
Мониторинг популяции диких животных — важная задача для мирового сообщества исследователей дикой природы. Ее решение помогает узнать, какие виды животных находятся под угрозой исчезновения, как они себя ведут в разные периоды жизни, где обитают и многое другое.
Для мониторинга животных используют различные инструменты, в том числе и фотоловушки — специальные камеры, устанавливаемые в лесу и реагирующие на движение в кадре. Каждый год с этих камер приходят сотни тысяч фотографий, на которых нужно найти и категоризировать животных. Это очень сложная и кропотливая работа, так как общее число видов может достигать нескольких сотен, могут встречаться и такие, которые визуально друг от друга трудно различимы. К тому же в кадр в момент активации камеры может попасть лишь часть животного, и из-за того, что активность многих видов приходится на ночное время суток, некоторые фотографии могут быть смазанными или засвеченными из специфики работы камер в ночное время.
В рамках Олимпиады НТО участникам предлагается помочь ученым автоматизировать рутинную работу по обработке данных с фотоловушек, обучив для этого модели машинного обучения.
Для мониторинга численности каждого вида животного участникам необходимо разработать классификатор фотографий животных по видам.
Для оценки качества работы модели используется macro F1 score: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html (pdf-версия страницы https://disk.yandex.ru/i/tRtB4WGtGfSFlQ).
Его особенность заключается в вычислении среднего арифметического F1 score по каждому классу. Значение метрики варьируется от 0 (в худшем случае) до 1, если все предсказания были корректны.
Подсчет метрики производится автоматически на платформе при отправке решения.
Датасет представляет собой набор изображений и файл train.csv с соответствием каждого изображения определенному виду животных.
Ниже представлена связь между индексом вида и его наименованием:
- — бурый медведь,
- — гималайский медведь,
- — кабан,
- — изюбрь,
- — пятнистый олень,
- — марал,
- — сибирская косуля,
- — азиатский барсук,
- — соболь,
- — амурский лесной кот,
- — манул,
- — рысь,
- — тигр,
- — ирбис,
- — аргали,
- — козерог,
- — волк,
- — лиса,
- — енотовидная собака,
- — заяц,
- — сурок.
Обратите внимание, что в датасете присутствуют сложные примеры: некоторые виды животных схожи между собой (например, сибирская косуля, пятнистый олень, изюбрь и марал), фото, когда в кадр попала небольшая часть животного, а также ночные и смазанные снимки.
Данные были размечены по видам учеными зоологами. В спорных случаях разметка подтверждалась несколькими экспертами.
Данные разделены на тренировочную и тестовую выборки в соотношении примерно 70% / 30%.
Тестовая часть разбита на публичную и приватную в соотношении примерно 40% / 60%.
Данные: https://disk.yandex.ru/d/Jx8fZJTSsk_LeQ
train.zip— архив с данными для обучения;train.csv— файл с разметкой для тренировочных данных;test.zip— тестовые данные, на которых нужно сделать предсказания;baseline.ipynb—jupyter-notebookс простым начальным решением;sample_submission.csv— пример файла с предсказаниями (все метки классов заполнены нулями).
Jupyter-notebook, позволяющий пройти путь от установки библиотек и обучения модели до получения файла с предсказаниями, который можно загрузить на платформу и увидеть метрики.
Формат входных данных
Соревнование подразумевает отправку файла с предсказаниями модели на платформу для расчета метрики. Сам файл представляет собой csv-документ с двумя колонками image_name и predicted_class. Строки — это пары с названием файла изображения и соответствующего ему индексу класса, который предсказала ваша модель.
Пример формирования корректного файла с предсказаниями.
Структура файла с предсказаниями, см. таблицу 1.2.
image_name |
predicted_class |
|---|---|
| 48daae9b7d2453e77a283be71fc5b2c0.JPG | 0 |
| 0a74e85fedb477adb3f71c9202bc3ddb.JPG | 0 |
| 9d5906140ff8487b33e4515a3aff98a4.JPG | 0 |
| 224b9c7024c0cea46c851f4eb9d9f662.JPG | 0 |
| 483693f497ace35bbfc60fc4142830f0.JPG | 0 |
Допускается использование открытых (доступных в сети) датасетов с лицензией, позволяющей свободное некоммерческое использование.
Разрабатывается алгоритм для классификации группы животных по фото с фотоловушек и представить его результат работы в виде csv-файла с колонками image_name, predicted_class.
Решением задачи будет csv-файл с предсказанием, загружаемый на платформу проведения соревнования для оценки качества решения. Пример загружаемого файла с решением: submission.csv.
Примечания
Разбор эталонного решения доступен по ссылке: https://gist.github.com/ntomaterials/b44ef19161f1dcb4259667d967abfbd2.





